第六章 逻辑回归(Logistic Regression)
6.1 Classification(分类问题)
从现在及未来,我们开始谈论的分类问题,其中要预测的变量$y$是
离散的(discreet valued)。我们将学习一个算法叫Logistic回归,这是当今最流行和最广泛使用的学习算法之一。下面是分类问题的一些例子。之前,我们谈到了
电子垃圾邮件分类就是一个分类问题。另一个例子是网上交易的分类问题。如果你有一个卖东西的网站,然后你想知道一次实物的交易是不是欺诈,或者某人是否在使用偷来的信用卡或者是盗用了别的用户的密码。这是另一种分类问题,之前我们也谈到肿瘤分类问题的例子,区别一个肿瘤是恶性的还是良性的。

- 在所有的这些问题中,我们需要预测的变量是变量$y$,我们可以认为它能够取两个值,要么是0,要么是1**,要么垃圾邮件要么不是垃圾邮件,欺诈性或不欺诈,恶性或良性。

- 标记为
0的类还有另一个名字叫做负类(negative class),标记为1的类,也叫做正类(positive class)。所以,0可能表示良性肿瘤 1也就是说正类可能表示一个恶性肿瘤。

- 对于这两种类别的分类,垃圾邮件,或者不是垃圾邮件,等等 将两种类别标记为,正类或负类,0或1是
任意的,其实怎样都可以。但是通常从直觉上来讲,负类总是表达缺少某样东西的意思,比如缺少恶性肿瘤,而1正类,就会表示 存在某样我们寻找的东西。但是哪个是负类,哪个是正类的定义,有时是任意的 这一点并不太重要。

- 现在,我们要开始研究只有两类 0和1的分类问题。稍后,我们将讨论多类别问题 多类别问题中的变量$y$ 的取值可以是0 1 2和3 或者更多。这就是所谓的多类分类问题,但是在接下来的几个视频中,让我们从两类分类问题 或者叫二元分类问题开始 我们以后再关心多类的问题

- 那么,我们应该如何建立一个分类算法?下面是一个训练集的例子 这个训练集是用来 给一个肿瘤分类为恶性或者良性的,注意 这个恶性值(malignancy) 只取两个值 0也就是
非(恶性)和1也即是是(恶性)
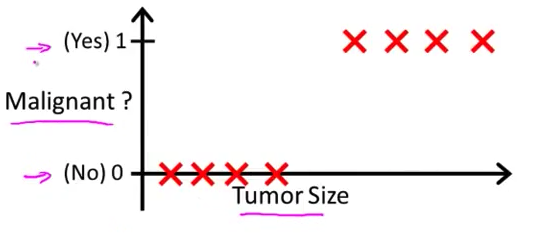
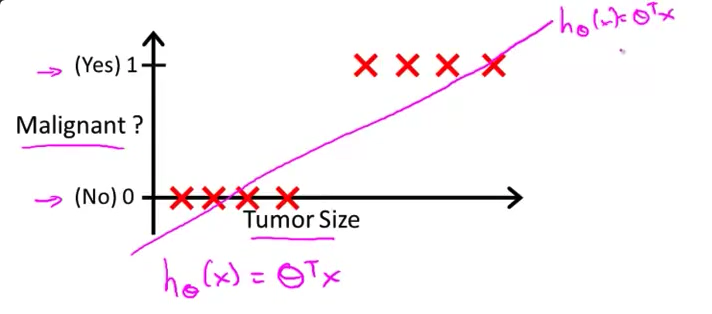
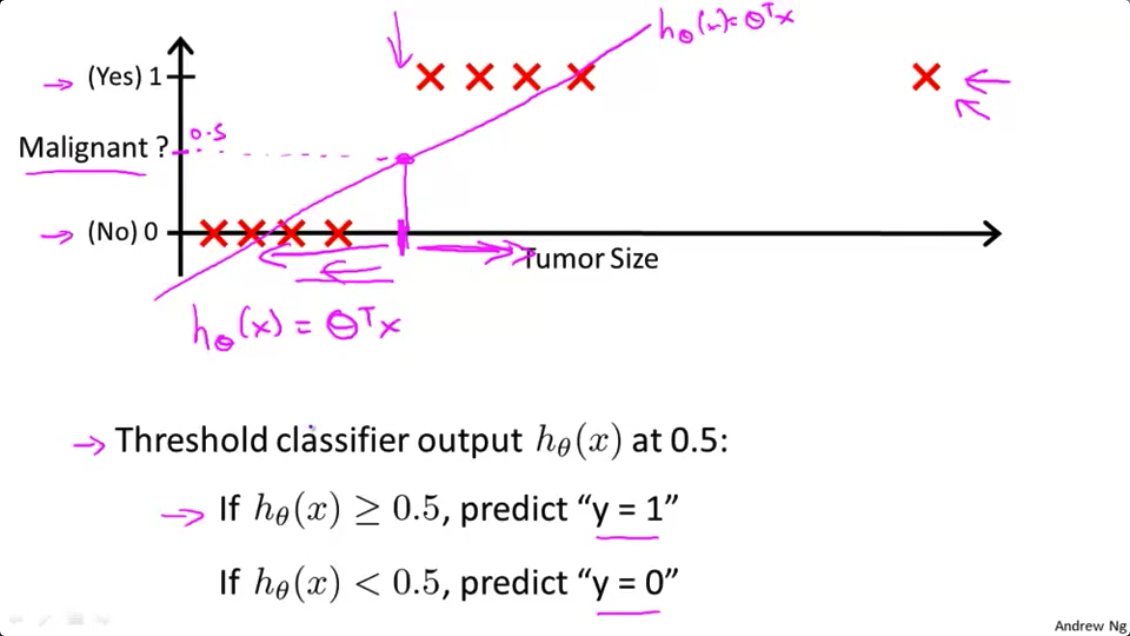
- 所以 拿到这个训练集 我们可以做的一个事情是 将一个我们已知的算法 线性回归用于这组数据 尝试用一条直线来拟合数据
所以如果用一条直线拟合这个训练集 你有可能得到 看起来像这样的假设函数。好了,所以这是我的假设函数$h_\theta(x)$ 等于 $\theta$ 的转置乘以$X$。
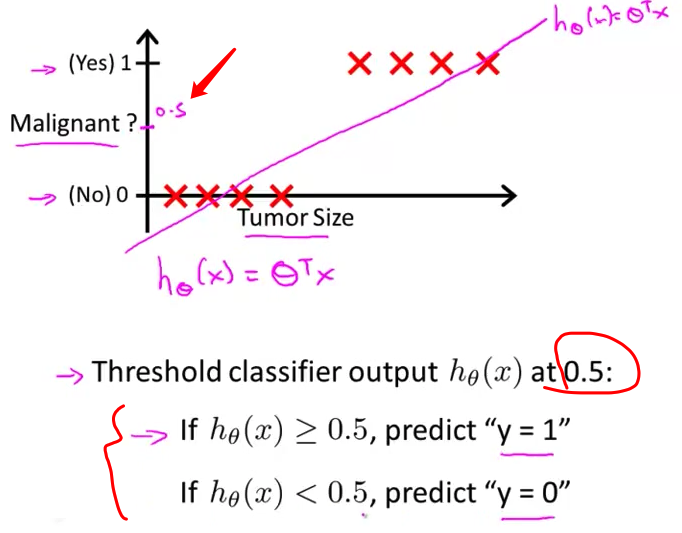
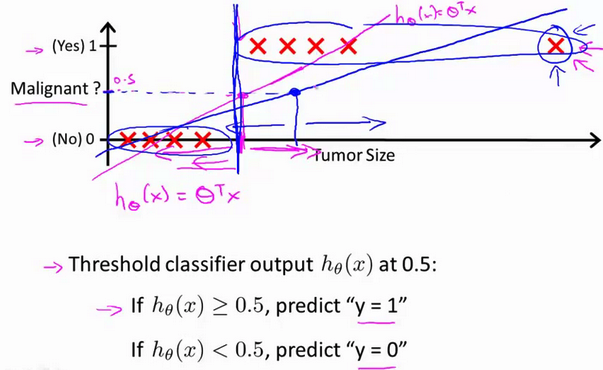
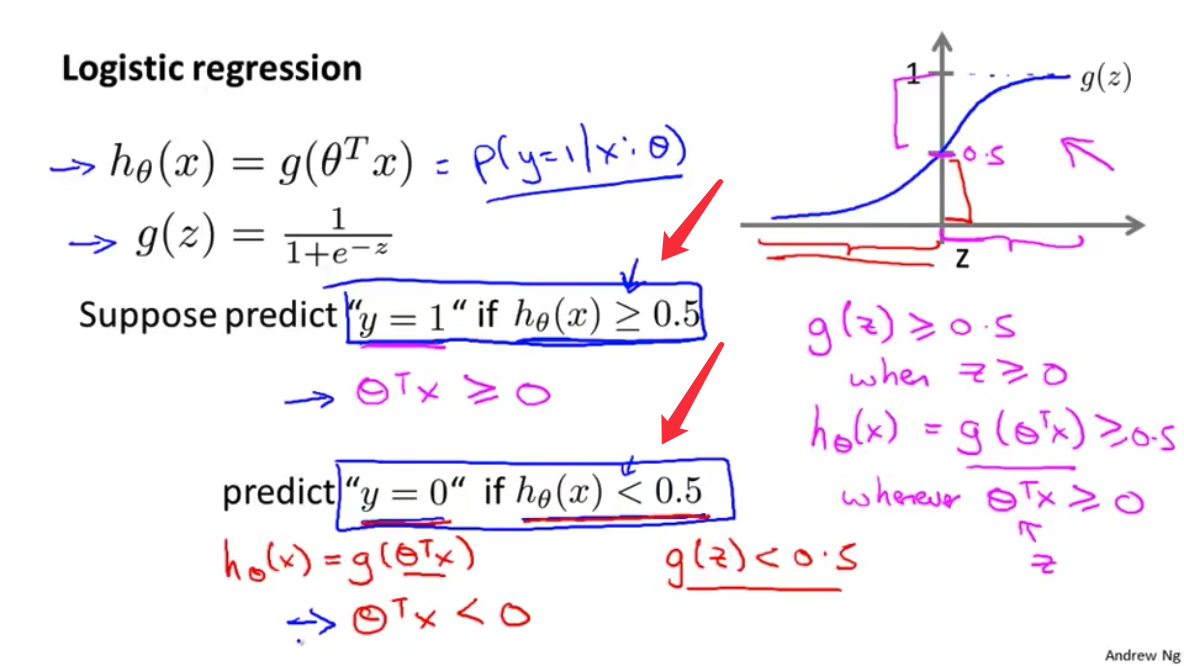
- 如果你想进行预测,你可以尝试将分类器的输出阈值设为0.5。这是纵轴上0.5的位置。 如果假设输出的值,大于等于0.5 你就预测$y$值等于1。如果小于0.5,你就预测$y$等于0。
- 让我们看看,当我们这样做的时候会发生什么。所以,让我们取
0.5,这就是阈值的位置。就这样使用线性回归算法,这个点(粉红色点)右边的所有点 我们会将它们全部预测为正类 因为它们的输出值都是大于0.5 在这一点的左侧的所有点,我们会预测它们全部为负。在这个特定的例子中,看起来好像线性回归所做的实际上是合理的 尽管我们感兴趣的是一个分类问题
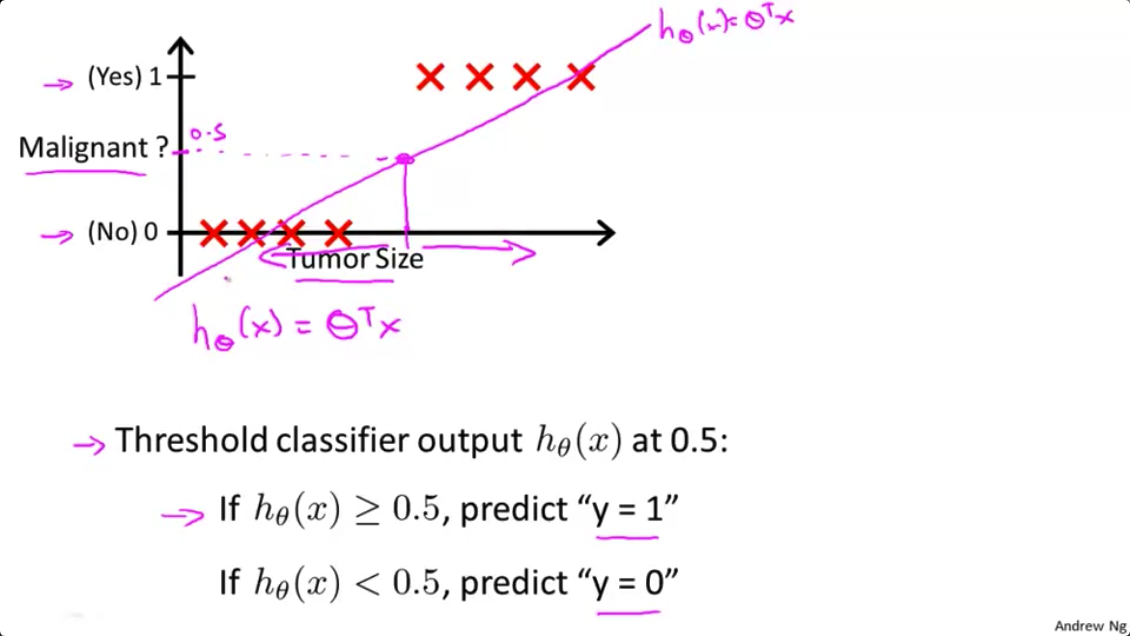
- 现在我们把问题稍微改一下。让我来延长一下横轴 假如说新增一个训练样本 在很远的右边那里 注意 这个额外的训练样本在这里,它实际上并没有改变什么,对不对?先看回之前的训练集,可以清晰看到这条直线是个好的hypothesis(假设函数)。好了,在这一点(横轴上的粉红色点)的右边所有点,我们应该预测为
正,左边所有点,我们应该预测为负因为对于这个训练集来说,所有肿瘤大小比中间的大的都是恶性的,比中间的小的都不是恶性的,至少在这个训练集中是这样子的。
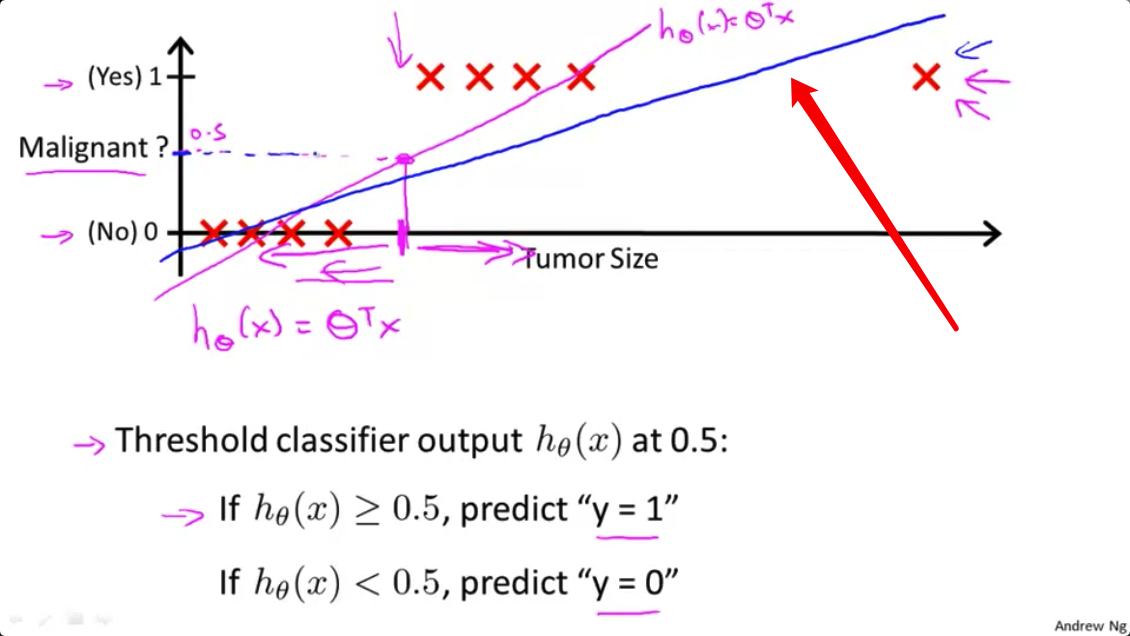
- 但是一旦我们在最右边这里增加了一个额外的训练样本,如果你现在运行线性回归算法,你不会得到一条拟合数据的直线。这可能是这样的蓝色直线
- 如果你现在将输出阈值设置为0.5,那么这个阈值点应该在蓝色那点上
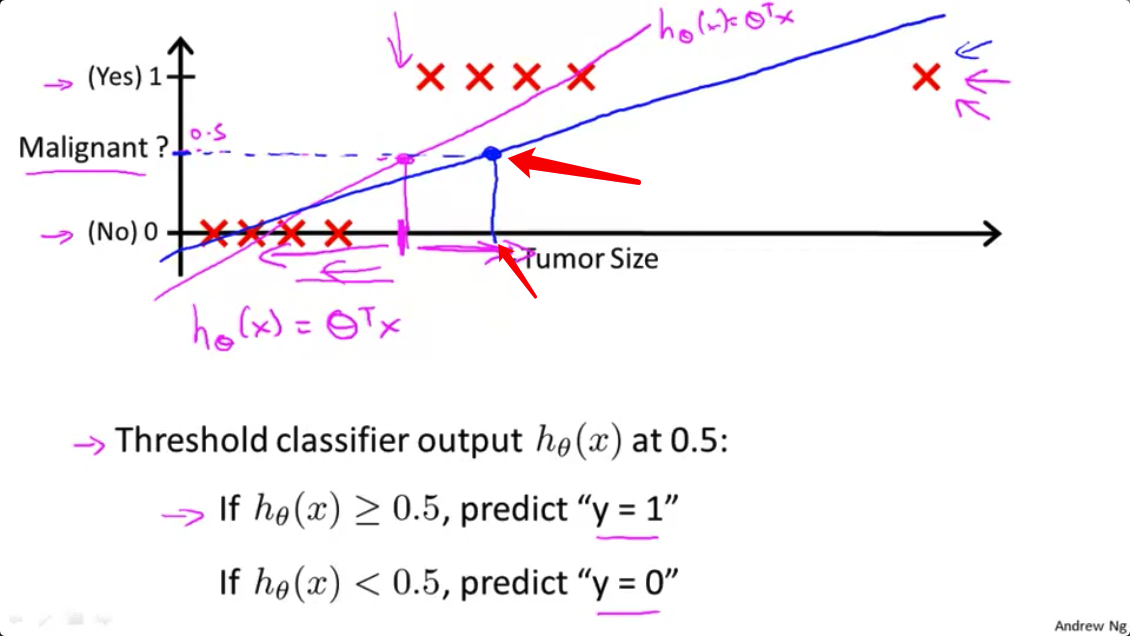
- 所以,在这点右边的所有点,你将预测为正,在这点左边的所有点,你将预测为负。然而,看起来这次试用线性回归算法得到了一个很坏的结果,对吧?因为,你知道,这些都是我们正的例子,这些都是我们的负的例子。这是很清楚的.
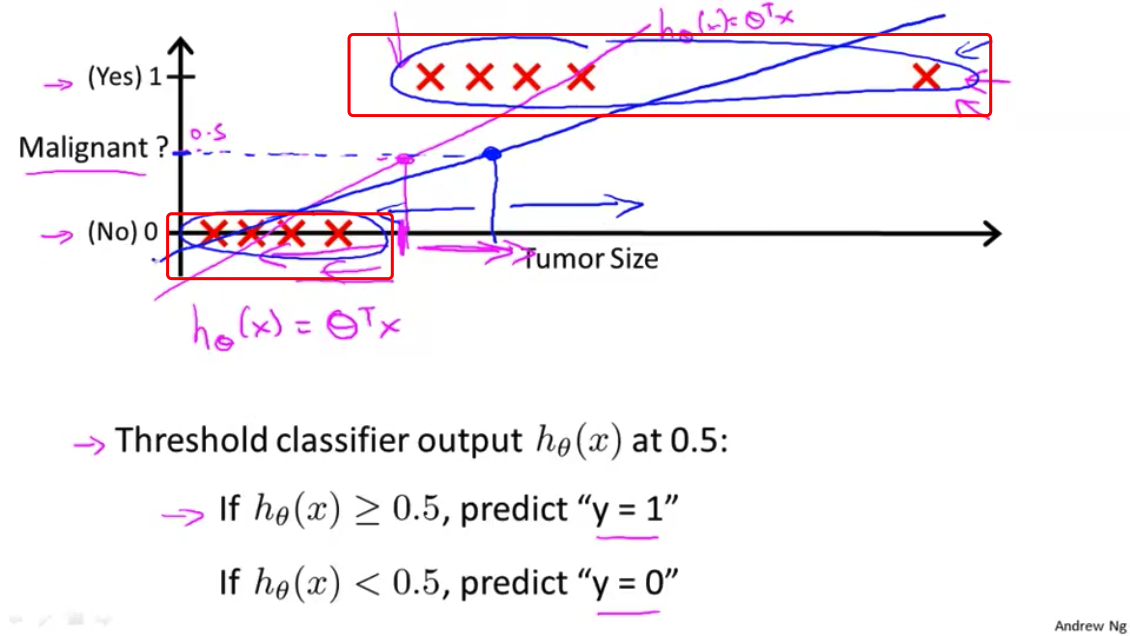
- 我们正确的划分应该在这里(蓝线)
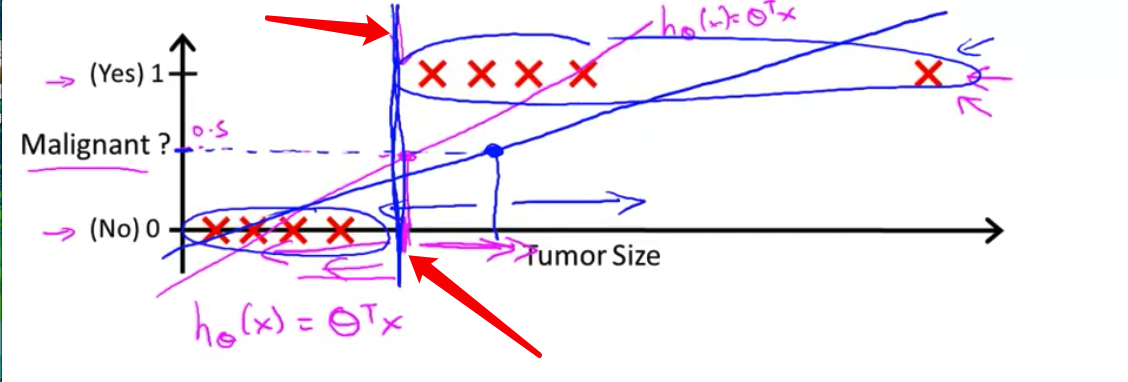
- 但不知何故在右边增加了一个训练样本,一个没有给我们更多新信息的训练样本 当然,对于这个假设函数来说 学习出了这个新增加的例子是恶性的 但不知何故,在那里新增加的训练样本引起了线性回归的直线拟合,该直线的拟合发生改变 从这个洋红色线条 变成了这个蓝线在这里,从而造成它给我们一个更坏的假设。
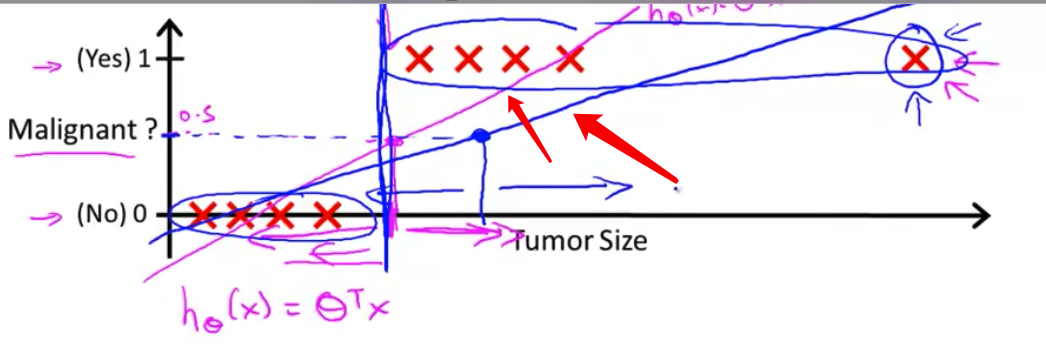
- 因此,应用线性回归到一个分类问题通常不是一个好主意。在第一个例子中,以我添加这个额外的训练例子为例,在添加之前,这个线性回归很巧合的,我们得到了一个运作良好假设 但通常给一个训练集使用线性回归,当然,你可能刚好巧合,但通常它不是一个好的想法,所以我不会对分类问题使用线性回归。
- 接下来是另外一个关于如果我们用线性回归处理分类问题会发生的有趣的事情。
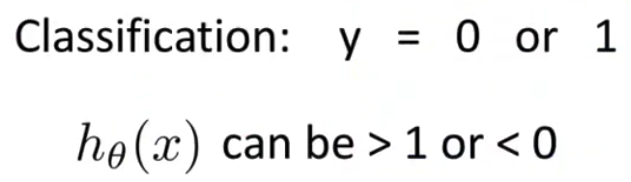
- 对于分类,我们知道,Y是0或1,但如果您使用的是线性回归,假设输出的值可能或远大于1或远小于0,即使所有好的训练样本都有标签Y 等于0或1 即使我们知道有标签为0或1,如果算法得出的结果比1大得多或者比0小得多 这似乎有点怪 所以,我们接下来的几个视频是学习所谓的
逻辑回归算法它具有一种输出的属性,就是逻辑回归预测的结果总是0和1之间,并不会大于1或小于零

- 顺便说一下,
logistic回归,我们将使用它作为分类算法,也许有时混淆了术语,它的名字上有”回归”,即使logistic回归实际上是一种分类算法。但是,这仅仅是它的名字被赋予历史的原因,所以不要被迷惑了。Logistic回归实际上是一种分类算法,当标签Y是离散值,零或一的时候。所以希望你现在知道是什么原因,使得你使用线性回归在分类问题上不是一个好主意。在接下来的视频中,我们将开始讨论logistic回归算法的细节。
小小的总结–分类问题
在分类问题中,你要预测的变量 $y$ 是离散的值,我们将学习一种叫做逻辑回归 (Logistic Regression) 的算法,这是目前最流行使用最广泛的一种学习算法。
在分类问题中,我们尝试预测的是结果是否属于某一个类(例如正确或错误)。分类问题的例子有:判断一封电子邮件是否是垃圾邮件;判断一次金融交易是否是欺诈;之前我们也谈到了肿瘤分类问题的例子,区别一个肿瘤是恶性的还是良性的。

我们从二元的分类问题开始讨论。
我们将因变量(dependent variable)可能属于的两个类分别称为负向类(negative class)和正向类(positive class),则因变量$y\in\{0,1\}$ ,其中 0 表示负向类,1 表示正向类。
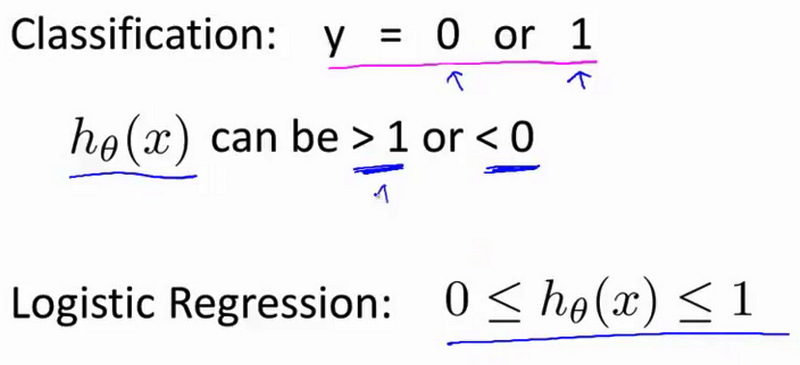
对于分类, $y$ 取值为 0 或者1,但如果你使用的是线性回归,那么假设函数的输出值可能远大于 1,或者远小于0,即使所有训练样本的标签 $y$ 都等于 0 或 1。尽管我们知道标签应该取值0 或者1,但是如果算法得到的值远大于1或者远小于0的话,就会感觉很奇怪。所以我们在接下来的要研究的算法就叫做逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。
顺便说一下,逻辑回归算法是分类算法,我们将它作为分类算法使用。有时候可能因为这个算法的名字中出现了“回归”使你感到困惑,但逻辑回归算法实际上是一种分类算法,它适用于标签 $y$ 取值离散的情况,如:1 0 0 1。
6.2 Hypothesis Representation(假说表示)
- 让我们开始谈谈逻辑回归 在这段视频中 我要给你展示假设函数的表达式 也就是说 在分类问题中 要用什么样的函数来表示我们的假设
- 此前我们说过 希望我们的分类器的输出值在0和1之间 因此 我们 希望想出一个 满足某个性质的假设函数 这个性质是它的预测值要在0和1之间
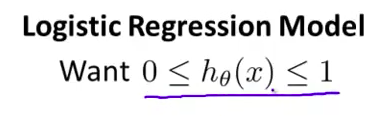
- 当我们使用线性回归的时候 这是一种假设函数的形式 其中 $h(x)=\theta^Tx$
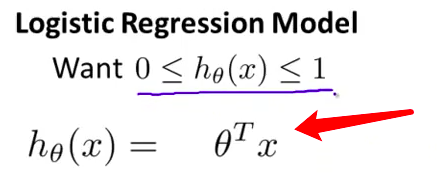
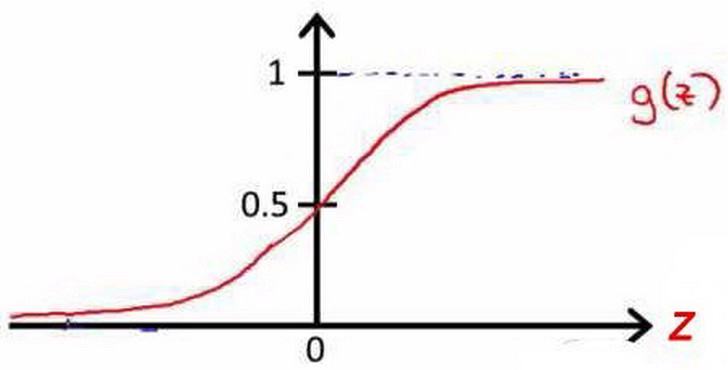
- 对于逻辑回归来说 我要把这个稍微改一下 把假设函数改成 $g(\theta^Tx)$ 其中 我将定义 函数$g$如下: 当$z$是一个实数时 $g(z)=\frac{1}{1+e^{-z}}$这称为
S 型函数 (sigmoid function)或逻辑函数(Logistic function)

- 逻辑函数这个词 就是逻辑回归名字的由来 顺便说一下 S型函数和逻辑函数基本上是同义词 意思是一样的 因此 这两个术语 基本上是可互换的 哪一个术语都可以 用来表示这个函数 $g$

- 如果我们 把这两个方程 合并到一起 这是我的假设 的另一种写法 也就是说 $h(x)=\frac{1}{1+e^{-\theta^Tx}}$
h(x)=1/(1+e^(-θ 转置乘以 x))我所做的是 把这个变量 $z$ 这里 $z$ 是一个实数 把 $\theta$ 的转置乘以 $x$ 代入到这里 所以最后得到的是 $\theta$ 转置乘以 $x$ 代替了这里的 $z$
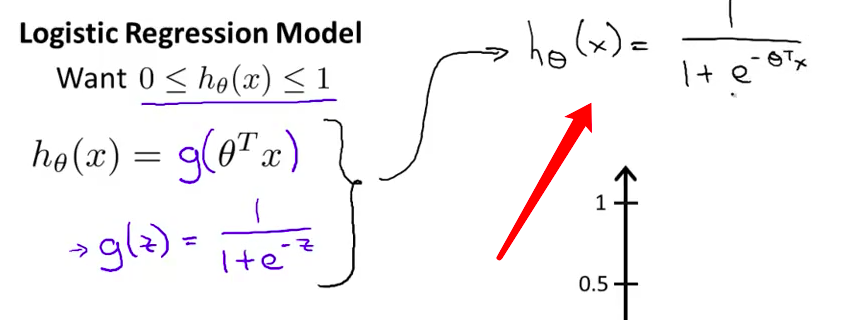
- 最后 我们看一下S型函数是什么样的 我们在这儿绘制这个图形 S型函数 $g(z)$ 也称为逻辑函数 看起来是这样的 它开始接近0 然后上升 直到在原点处达到0.5 然后它再次变平 像这样 所以这就是
S型函数的样子
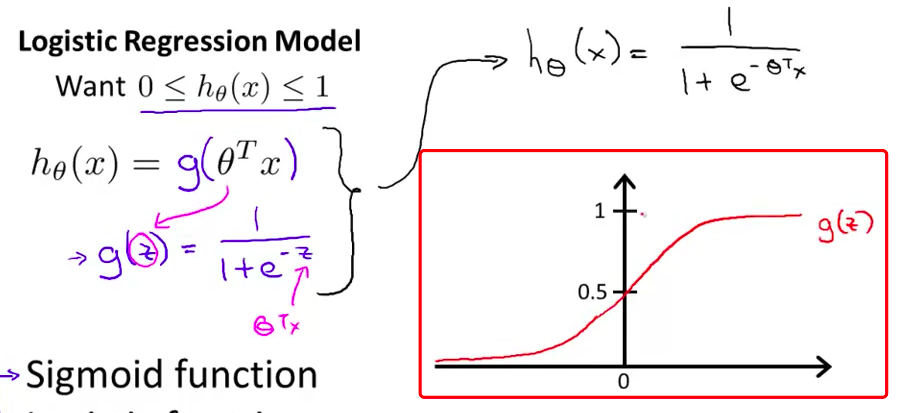
- 而且你注意S型函数 它渐近于1 然后随着横坐标 的反方向趋向于0 随着 $z$ 趋于负无穷 $g(z)$ 趋近于零 随着 $z$ 趋于正无穷 $g(z)$ 趋近于1 因为 $g(z)$ 的取值 在0和1之间 我们就得到 $h(x)$ 的值 必在0和1之间
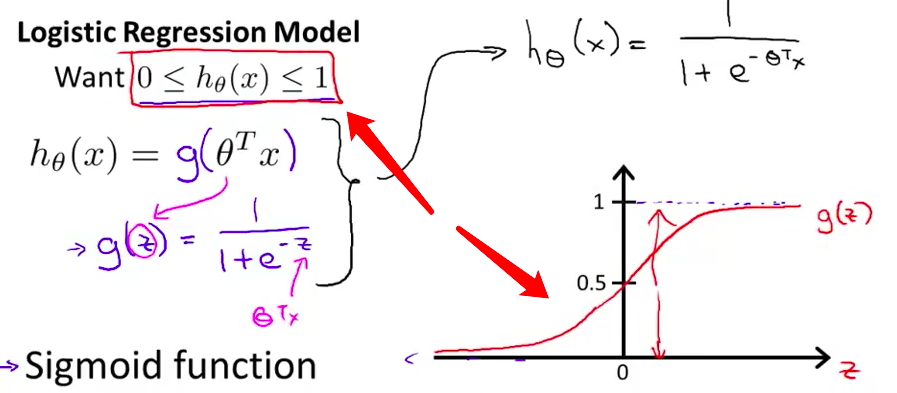
- 最后 有了这个假设函数 我们需要做的是 和之前一样 用参数$\theta$拟合我们的数据 所以拿到一个训练集 我们需要给参数 $\theta$ 选定一个值 然后用这个假设函数做出预测 稍后我们将讨论一个 用来拟合参数$\theta$的学习算法 但是首先让我们讨论 一下这个模型的解释
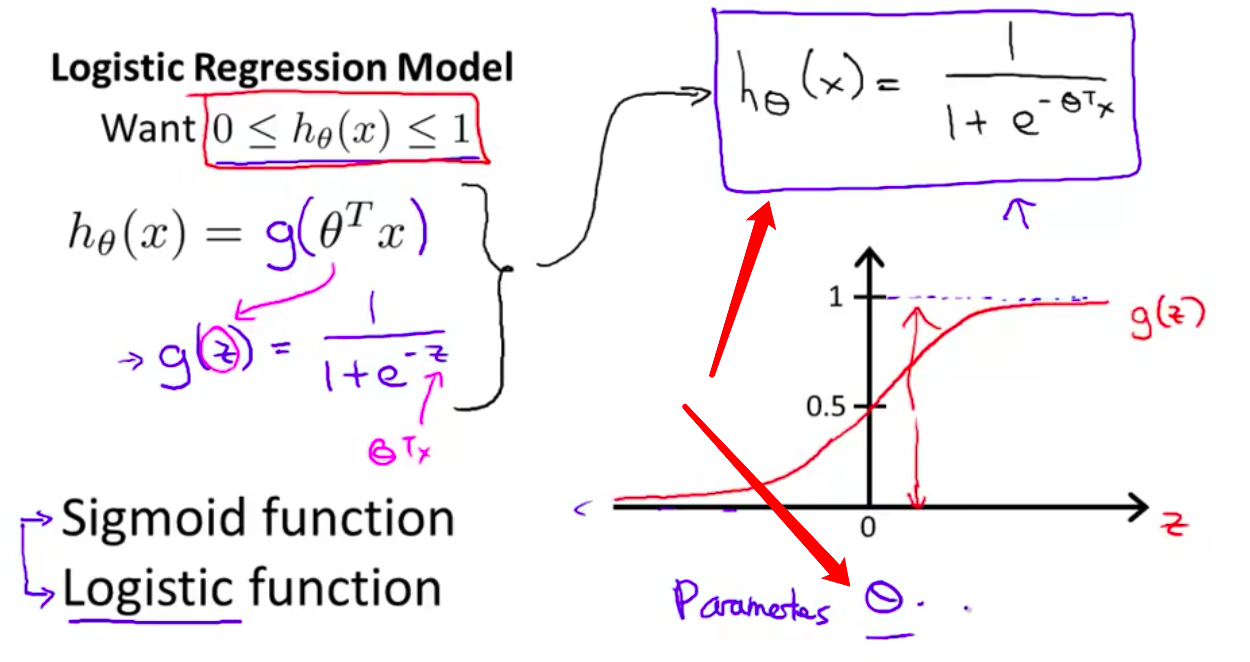
- 这就是我对 假设函数 $h(x)$ 的输出的解释: 当我的假设函数 输出某个数 我会认为这个数是 对于新输入样本 $x$ 的
y 等于1的概率的估计值 我的意思是这样的

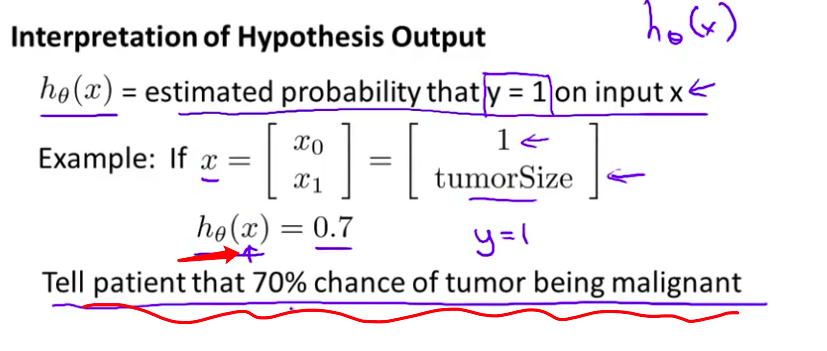
- 下面举个例子 比方说 我们来看肿瘤分类的例子 我们有一个特征向量 $x$ 和平时一样 $x_0$ 等于 1 然后我们的特征变量
x1是肿瘤的大小

- 假设我有一个病人来了 而且知道
肿瘤的大小把他的特征向量 $x$ 代入我的假设函数 假如假设函数的输出为0.7 我将解释 我的假设如下 我要说 这个 假设告诉我 对于一个特征为 $x$ 的患者 $y$ 等于 1 的概率是0.7 换句话说 我要告诉我的病人 非常遗憾 肿瘤是恶性的可能性是70%或者说0.7
- 要更加正式的写出来 或者说写成数学表达式 我的假设函数等于
P(y=1|x;θ)对于熟悉概率的人 应该能看懂这个式子 如果你不太熟悉概率 可以这么看这个表达式 在给定 $x$ 的条件下 $y=1$ 的概率 给定的 $x$ 就是我的病人的特征, $x$ 特征代表了 我的病人特定的肿瘤大小 这个概率的参数是 $\theta$ 所以 我基本上可以认为 假设函数给出的估计 是 $y=1$ 的概率

- 现在 因为这是一个 分类的任务 我们知道 $y$ 必须是0或1 对不对? 它们是 $y$ 可能取到的 仅有的两个值 无论是在训练集中 或是对走进我的办公室 或在未来进入医生办公室的新患者 因此 有了 $h(x)$ 我们也可以计算 $y=0$ 的概率 具体地说 因为 $y$ 必须是0或1 我们知道 $y=0$ 的概率 加上 $y=1$ 的概率 必须等于1 这第一个方程看起来 有点复杂 基本上就是说 给定参数 $\theta$ 对某个特征为 $x$ 的病人 $y=0$ 的概率 和给定参数 $\theta$ 时 对同一个特征为 $x$ 的病人 $y=1$ 的概率相加 必须等于1

- 如果觉得这个方程看到起来有点儿复杂 可以想象它没有 $x$ 和 $\theta$ 这就是说 $y=0$ 的概率 加上 $y=1$ 的概率必须等于1 我们知道这是肯定的 因为 $y$ 要么是0 要么是1 所以 $y=0$ 的可能性 和 $y=1$ 的可能性 它们俩相加肯定等于1
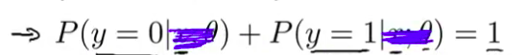
- 所以 如果你只是 把这一项 移到右边 你就会得到这个等式 就是说 $y=0$ 的概率 等于1减去 $y=1$ 的概率 因此 我们的 假设函数 $h(x)$ 给出的是这一项 你可以简单地计算出这个概率 计算出 $y=0$ 的概率的估计值 所以 你现在知道 逻辑回归的假设函数的表达式是什么 我们看到了定义逻辑回归的 假设函数的数学公式 在接下来的视频中 我想试着让你 对假设函数是什么样子 有一个更直观的认识 我想告诉你 一个被称为
判定边界 (decision)的东西 我们会一起看一些可视化的东西 可以更好地理解 逻辑回归的假设函数 到底是什么样子
小小的总结–假说表示
在这段视频中,我要给你展示假设函数的表达式,也就是说,在分类问题中,要用什么样的函数来表示我们的假设。此前我们说过,希望我们的分类器的输出值在0和1之间,因此,我们希望想出一个满足某个性质的假设函数,这个性质是它的预测值要在0和1之间。
回顾在一开始提到的乳腺癌分类问题,我们可以用线性回归的方法求出适合数据的一条直线:
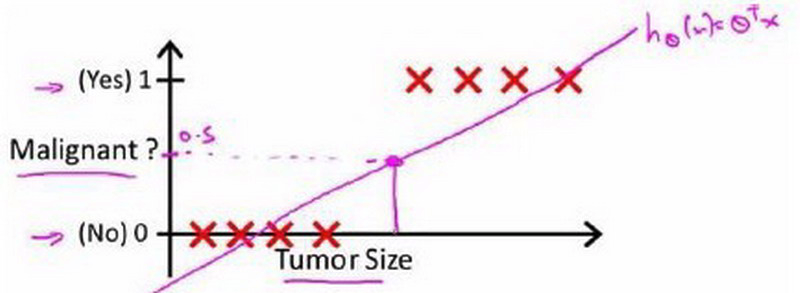
根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们需要输出0或1,我们可以预测:
当 ${h_\theta}\left(x\right)$ 大于等于0.5时,预测 $y=1$。
当 ${h_\theta}\left(x\right)$ 小于0.5时,预测 $y=0$ 。
对于上图所示的数据,这样的一个线性模型似乎能很好地完成分类任务。假使我们又观测到一个非常大尺寸的恶性肿瘤,将其作为实例加入到我们的训练集中来,这将使得我们获得一条新的直线。
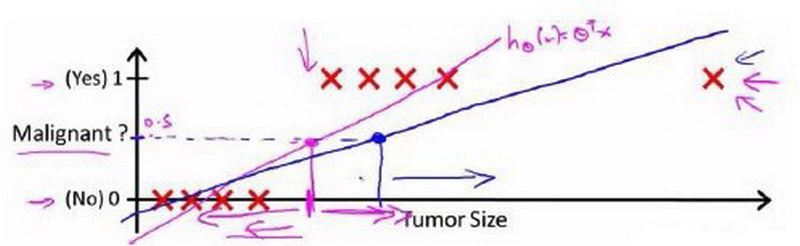
这时,再使用0.5作为阀值来预测肿瘤是良性还是恶性便不合适了。可以看出,线性回归模型,因为其预测的值可以超越[0,1]的范围,并不适合解决这样的问题。
我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在0和1之间。
逻辑回归模型的假设是: $h_\theta \left( x \right)=g\left(\theta^{T}X \right)$
其中:
python代码实现:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))该函数的图像为:
合起来,我们得到逻辑回归模型的假设:
对模型的理解: $g\left( z \right)=\frac{1}{1+{{e}^{-z}}}$。
$h_\theta \left( x \right)$的`作用`是,**对于给定的输入变量,根据选择的参数计算输出变量=1的可能性**(estimated probablity)即$h_\theta \left( x \right)=P\left( y=1|x;\theta \right)$例如,如果对于给定的x,通过已经确定的参数计算得出$h_\theta \left( x \right)$=0.7,则表示有70%的几率y为正向类,相应地y为负向类的几率为1-0.7=0.3。

6.3 Decision boundary(决策边界)
- 在过去的视频中 我们谈到 逻辑回归中假设函数的表示方法 现在 我想 告诉大家一个叫做
决策边界(decision boundary)的概念 这个概念能更好地帮助我们 理解逻辑回归的 假设函数在计算什么 - 让我们回忆一下 这是我们上次写下的公式 当时我们说 假设函数可以表示为 $h(x)=g(\theta^Tx)$ 其中函数$g$被称为
S形函数(sigmoid function)看起来是应该是这样的形状 它从零开始慢慢增加至1 逐渐逼近1

- 现在让我们 更进一步来理解 这个假设函数何时 会将$y$预测为1 什么时候又会将 $y$预测为0 让我们更好的理解 假设函数的应该是怎样的 特别是当我们的数据有多个特征时
- 具体地说 这个假设函数 输出的是 给定$x$时 $y=1$的概率
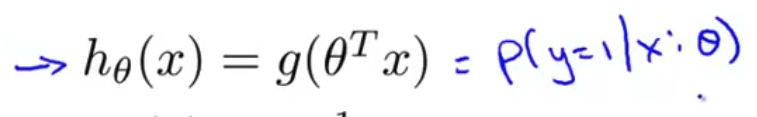
- 因此 如果我们想 预测$y=1$ 还是等于0 我们可以这样做 只要该假设函数 输出$y=1$的概率 大于或等于0.5 那么这表示 $y$更有可能 等于1而不是0 因此 我们预测$y=1$

- 在另一种情况下 如果 预测$y=1$ 的概率 小于0.5 那么我们应该预测$y=0$

- 在这里 我选择大于等于 在这里我选择小于 如果$h(x)$的值 正好等于0.5 那么 我们可以预测为1 也可以预测为0 但是这里我选择了大于等于 因此我们默认 如果$h(x)$等于0.5的话 预测选择为1 这只是一个细节 不用太在意

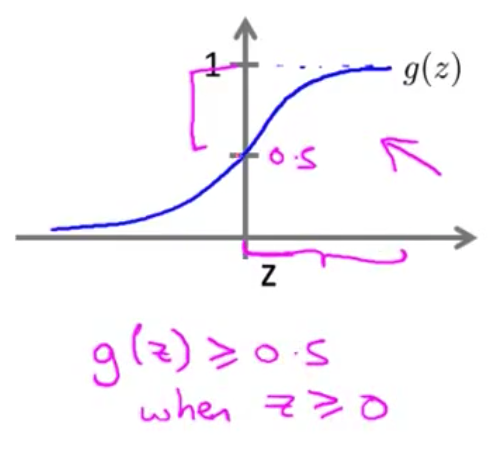
- 下面 我希望大家能够 清晰地理解 什么时候$h(x)$ 将大于或等于 0.5 从而 我们最终预测$y=1$ 如果我们看看 S形函数的曲线图 我们会注意到
S函数只要$z$大于 或等于0时 $g(z)$就将大于 或等于0.5 因此 在曲线图的这半边 $g$的取值 大于或等于0.5 因为这个交点就是0.5 因此 当$z$大于0时 $g(z)$ 也就是这个 S形函数 是大于或等于0.5的
- 由于逻辑回归的 假设函数$h(x)$ 等于$g(\theta^Tx)$ 因此 只要$\theta^Tx$ 大于或等于0 函数值将会 大于或等于0.5
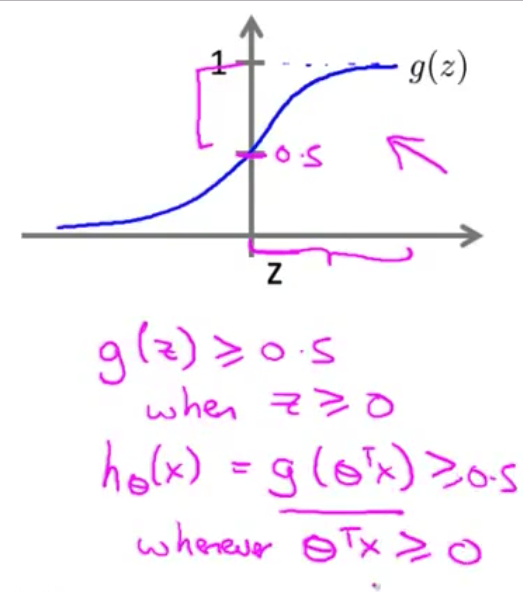
- 因此 我们看到 因为这里$\theta^Tx$ 取代了$z$的位置 所以我们看到 只要$\theta^Tx$ 大于或等于0 我们的假设函数 将会预测$y=1$

- 现在让我们来考虑 假设函数 预测$y=0$的情况 类似的 只要 $g(z)$小于0.5 $h(\theta)$将会 小于0.5 这是因为 $z$的定义域上 导致$g(z)$取值 小于0.5的部分 是$z$小于0的部分 所以当$g(z)$小于0.5时 我们的假设函数将会预测 $y=0$ 根据与之前 类似的原因 $h(x)=g(\theta^Tx)$ 因此 只要 $\theta^Tx$小于0 我们就预测$y$等于0
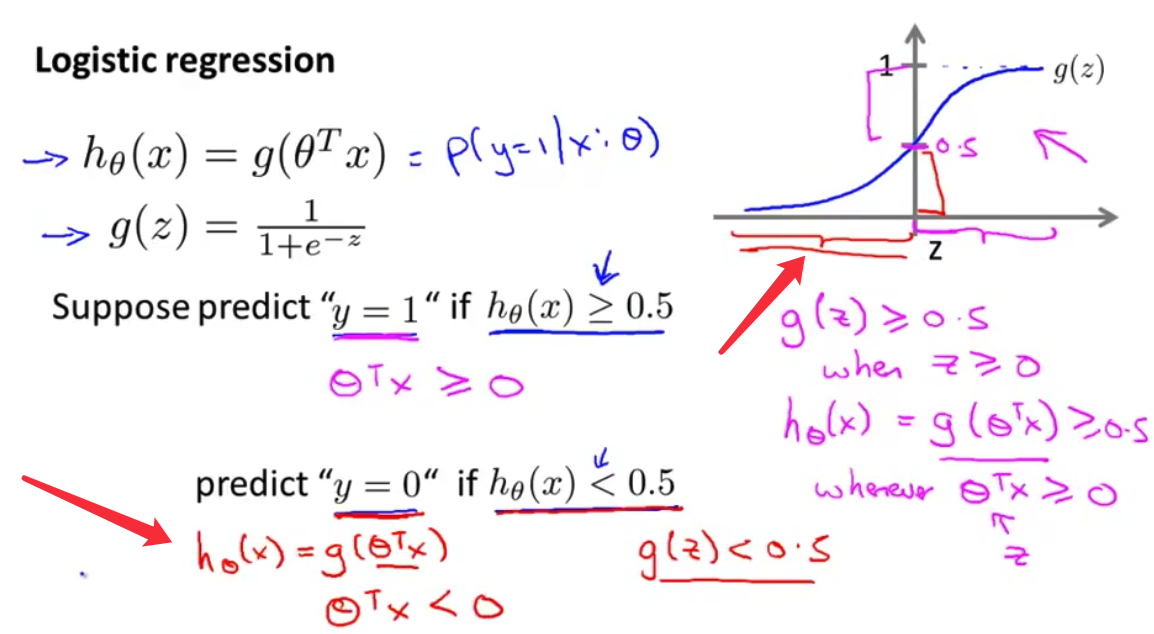
- 总结一下我们刚才所讲的 我们看到 如果我们要决定 预测$y=1$ 还是$y=0$ 取决于 $y=1$的概率 大于或等于0.5 还是小于0.5 这其实就等于说 只需要$\theta^Tx$ 大于或等于0 我们将预测$y=1$ 另一方面只需要$\theta^Tx$ 小于0 我们将预测$y=0$ 通过这些 我们能更好地 理解如何利用逻辑回归的假设函数 来进行预测
- 现在假设我们有 一个训练集 就像下图的这个 接下来我们假设我们的假设函数是 $h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2)$ 目前我们还没有谈到 如何拟合此模型中的参数 我们将在下一个视频中讨论这个问题 但是假设我们 已经拟合好了参数 我们最终选择了如下值 比方说 我们选择$\theta_0$ 等于-3 $\theta_1$ 等于1 $\theta_2$等于1 因此 这意味着我的 参数向量将是 $\theta$等于[-3 1 1]
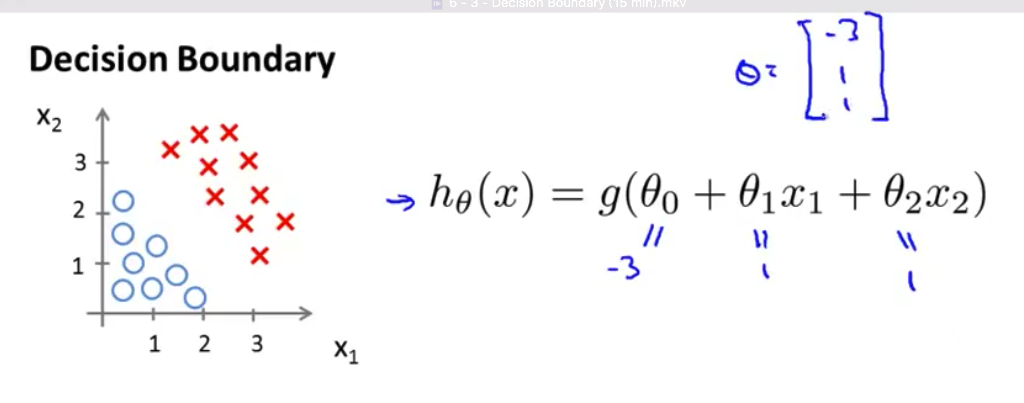
- 这样 我们有了 这样的一个参数选择 让我们试着找出 假设函数何时将 预测$y$等于1 何时又将预测$y$等于0 使用我们在 在上一张幻灯片上展示的公式 我们知道 只要$\theta^Tx$ 大于0 $y$更有可能是1 或者说 $y$等于1的概率 大于0.5 或者大于等于0.5 我刚刚加了下划线的 这个公式 $-3+x_1+x_2$ 当然就是$\theta^Tx$ 这是当$\theta$等于 我们选择的这个参数值时 $\theta^Tx$的表达

- 因此 举例来说 对于任何样本 只要$x_1$和$x_2$满足 这个等式 也就是$-3+x_1+x_2\geq0$ 我们的假设函数就会认为 $y$等于1 的可能性较大 或者说将预测$y=1$

- 我们也可以 将$-3$放到不等式右边 并改写为 $x_1+x_2\geq3$ 这样是等价的 我们发现 只要 $x_1+x_2\geq3$ 这一假设函数将预测 $y=1$

- 让我们来看看这在图上是什么意思 如果我写下等式 $x_1+x_2=3$ 这将定义一条直线 如果我画出这条直线 它将表示为 这样一条线 它通过 通过$x_1$轴上的3 和$x_2$轴上的3 因此 这部分的输入样本空间 这一部分的
X1-X2平面 对应$x_1+x_2\geq3$ 这将是上面这个半平面 也就是所有 上方和所有右侧的部分 相对我画的这条洋红色线来说 所以 我们的假设函数预测 $y=1$的区域 就是这片区域 是这个巨大的区域 是右上方的这个半平面 让我把它写下来 我将称它为 $y=1$区域
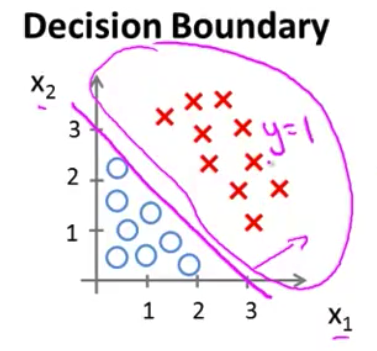
- 与此相对 $x_1+x_2<3$的区域 也就是我们预测 $y$等于0的区域 是这一片区域 你看到 这也是一个半平面 左侧的这个半平面 是我们的假设函数预测y等于0的区域< li>
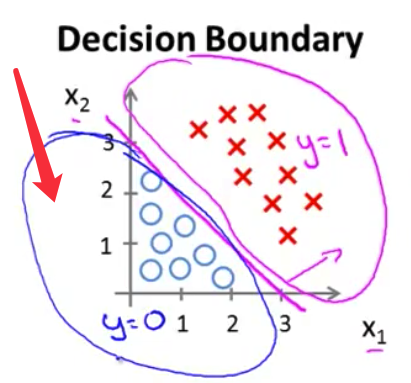
- 我想给这条线一个名字 就是我刚刚画的这条洋红色线 这条线被称为
决策边界(decision boundary)具体地说 这条直线 满足$x_1+x_2=3$ 它对应一系列的点 它对应 $h(x)$等于 0.5的区域 决策边界 也就是 这条直线 将整个平面分成了两部分 其中一片区域假设函数预测$y$等于1 而另一片区域 假设函数预测$y$等于0
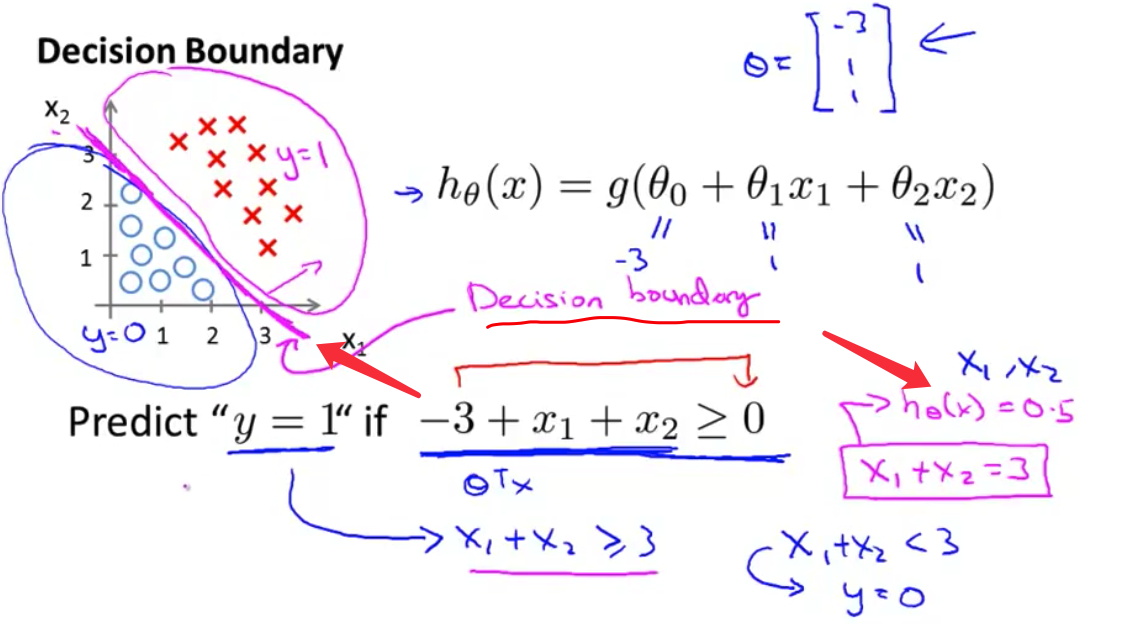
- 我想澄清一下 决策边界是 假设函数的一个属性 它包括参数$\theta_0,\theta_1,\theta_2$ 在这幅图中 我画了一个训练集 我画了一组数据 让它更加可视化 但是 即使我们 去掉这个数据集 这条决策边界 和我们预测$y$等于1 与$y$等于0的区域 它们都是 假设函数的属性 决定于其参数 它不是数据集的属性 当然 我们后面还将讨论 如何拟合参数 那时 我们将 使用训练集 使用我们的数据 来确定参数的取值 但是 一旦我们有确定的参数取值 有确定的$\theta_0,\theta_1,\theta_2$ 我们就将完全确定 决策边界 这时 我们实际上并不需要 在绘制决策边界的时候 绘制训练集
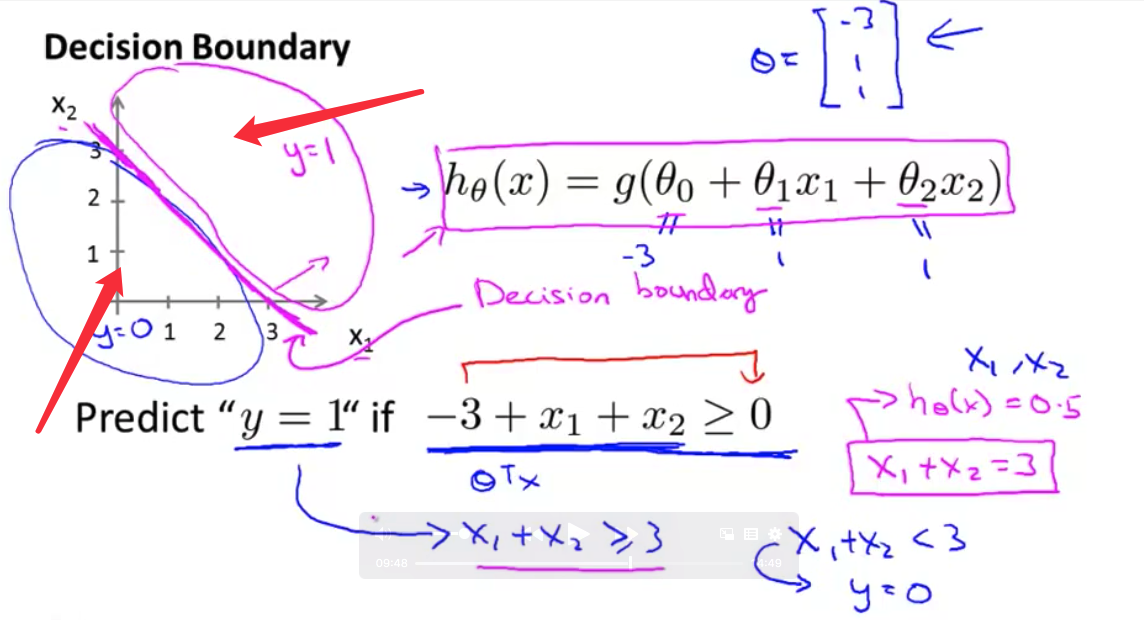
- 现在 让我们看一个 更复杂的例子 和往常一样 我使用十字 (X) 表示我的
正样本圆圈 (O) 的表示我的负样本给定这样的一个训练集 我怎样才能使用逻辑回归 拟合这些数据呢?
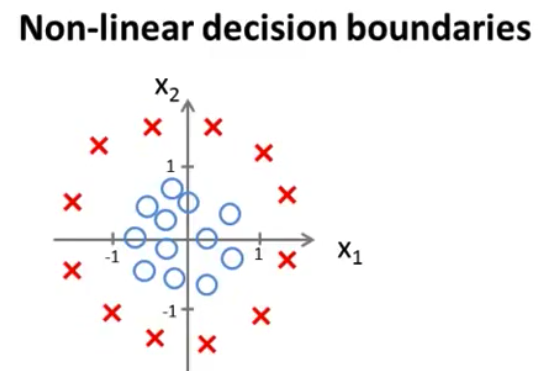
- 早些时候 当我们谈论 多项式回归 或线性回归时 我们谈到可以添加额外的
高阶多项式项同样我们也可以对逻辑回归使用相同的方法 具体地说 假如我的假设函数是这样的 $h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1^2+\theta_4x_2^2)$ 我已经添加了两个额外的特征 $x_1^2$和$x_2^2$ 所以 我现在有5个参数 $\theta_0$ 到 $\theta_4$ 之前讲过 我们会 在下一个视频中讨论 如何自动选择 参数$\theta_0$ 到 $\theta_4$的取值 但是 假设我 已经使用了这个方法 我最终选择$\theta_0$等于-1 $\theta_1$等于0 $\theta_2$等于0 $\theta_3$等于1 $\theta_4$等于1 这意味着 在这个参数选择下 我的参数向量 $\theta$将是[-1 0 0 1 1]
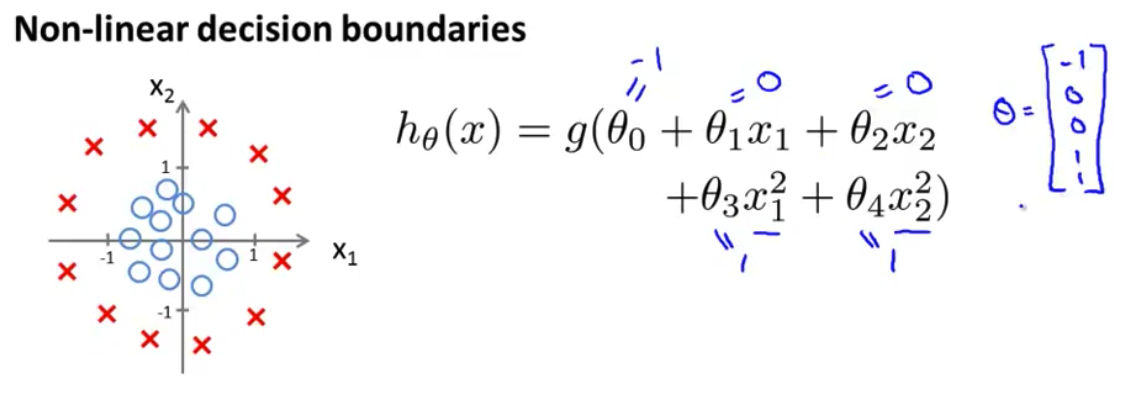
- 根据我们前面的讨论 这意味着 只要$-1+x_1^2+x_2^2\geq0$ 我的假设函数将预测
y=1也就是$\theta^Tx$大于等于0的时候 如果我将 -1放到不等式右侧 我可以说 只要$x_1^2+x_2^2\geq1$ 我的假设函数将预测 $y=1$

- 那么决策边界是什么样子的呢? 好吧 如果我们绘制 $x_1^2+x_2^2=1$的曲线 你们有些人已经 知道这个方程对应 半径为1 原点为中心的圆 所以 这就是我们的决策边界
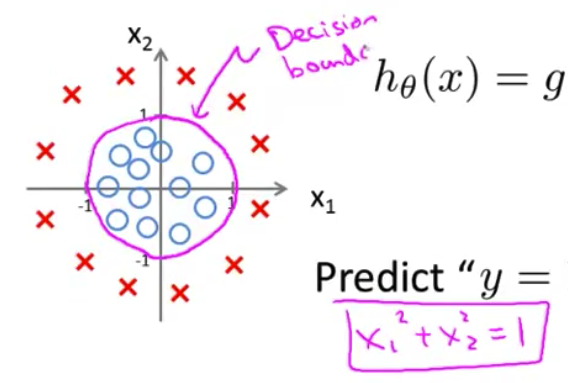
- 圆外面的一切 我将预测 $y=1$ 所以这里就是 y等于1的区域 我们在这里预测$y=1$ 而在圆里面 我会预测$y=0$
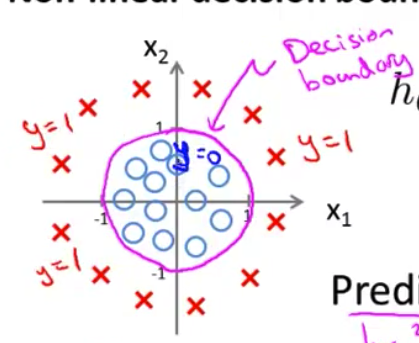
- 因此 通过增加这些 复杂的多项式特征变量 我可以得到更复杂的决定边界 而不只是 用直线分开正负样本 在这个例子中 我可以得到 一个圆形的决策边界 再次强调 决策边界 不是训练集的属性 而是假设本身及其参数的属性 只要我们 给定了参数向量$\theta$ 圆形的决定边界 就确定了 我们不是用训练集来定义的决策边界 我们用训练集来拟合参数$\theta$ 以后我们将谈论如何做到这一点 但是 一旦你有 参数$\theta$它就确定了决策边界

- 让我重新显示训练集 以方便可视化 最后 让我们来看看一个更复杂的例子 我们可以得到 更复杂的决策边界吗? 如果我有 高阶多项式特征变量 比如$x_1^2$, $x_1^2x_2$ $x_1^2x_2^2$ 等等 如果我有更高阶 多项式 那么可以证明 你将得到 更复杂的决策边界 而逻辑回归 可以用于找到决策边界 例如 这样一个椭圆 或者参数不同的椭圆
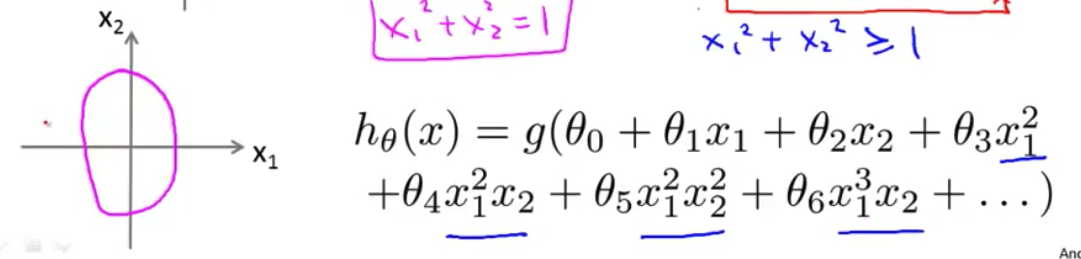
- 也许你 可以得到一个不同的决定边界 像这个样子 一些有趣的形状 或者更为复杂的例子 你也可以得到决策边界 看起来这样 这样更复杂的形状 在这个区域 你预测$y=1$ 在这个区域外面你预测$y=0$ 因此 这些高阶多项式 特征变量 可以让你得到非常复杂的决策边界 因此 通过这些可视化图形 我希望告诉你 什么范围的假设函数 我们可以使用 逻辑回归来表示 现在我们知道了$h(x)$表示什么 在下一个视频中 我将介绍 如何自动选择参数$\theta$ 使我们能在给定一个训练集时 我们可以根据数据自动拟合参数
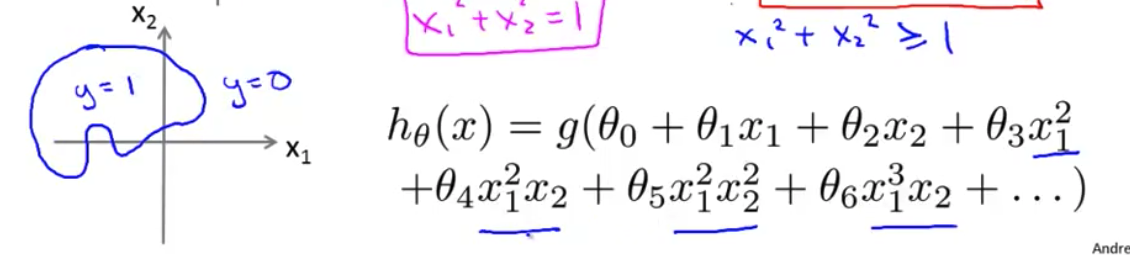
小小的总结–决策边界
现在讲下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。

在逻辑回归中,我们预测:
当$h_\theta \left( x \right)$大于等于0.5时,预测 $y=1$。
当$h_\theta \left( x \right)$小于0.5时,预测 $y=0$ 。
根据上面绘制出的 S 形函数图像,我们知道当
$z=0$ 时 $g(z)=0.5$ $z>0$ 时 $g(z)>0.5$ $z<0$ 时 $g(z)<0.5$又 $z={\theta^{T}}x$ ,即:
${\theta^{T}}x$ 大于等于 0 时,预测 $y=1$ ${\theta^{T}}x$ 小于 0 时,预测 $y=0$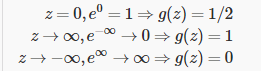
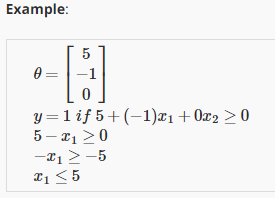
现在假设我们有一个模型:
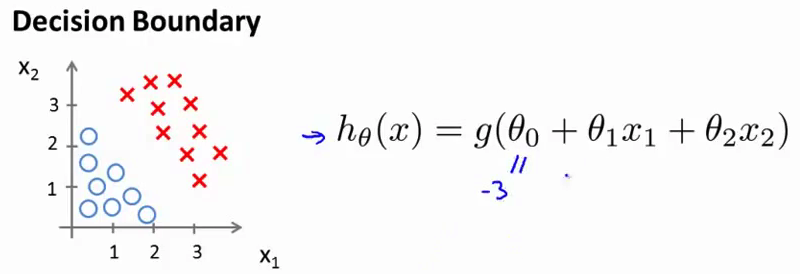
并且参数$\theta$ 是向量[-3; 1; 1]。 则当$-3+{x_1}+{x_2} \geq 0$,即${x_1}+{x_2} \geq 3$时,模型将预测 $y=1$。
我们可以绘制直线${x_1}+{x_2} = 3$,这条线便是我们模型的分界线,将预测为1的区域和预测为 0的区域分隔开。
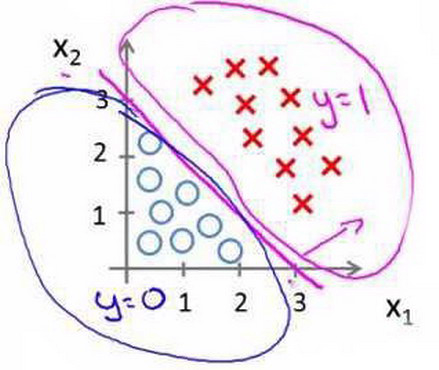
假使我们的数据呈现这样的分布情况,怎样的模型才能适合呢?
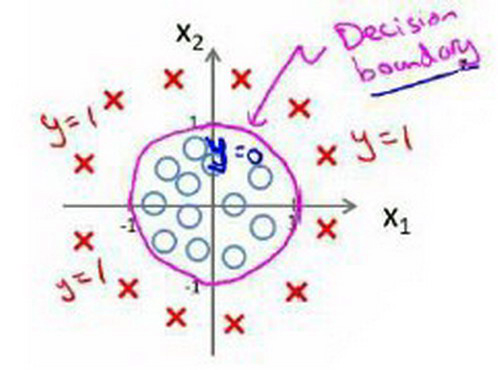
因为需要用曲线才能分隔 y=0 的区域和 y=1 的区域,我们需要二次方特征:${h_\theta}\left( x \right)=g\left( {\theta_0}+{\theta_1}{x_1}+{\theta_{2}}{x_{2}}+{\theta_{3}}x_{1}^{2}+{\theta_{4}}x_{2}^{2} \right)$是[-1 0 0 1 1],则我们得到的判定边界恰好是圆点在原点且半径为1的圆形。

我们可以用非常复杂的模型来适应非常复杂形状的判定边界。
6.4 Cost Function(代价函数)
- 在这段视频中 我们要讲如何拟合逻辑回归模型的参数$\theta$具体来说 我要定义用来拟合参数的优化目标或者叫
代价函数 - 这便是监督学习问题中的逻辑回归模型的拟合问题 我们有一个训练集 里面有$m$个训练样本 像以前一样 我们的每个样本 用$n+1$维的特征向量表示 同样和以前一样 第一个特征变量或者说第0个特征变量 一直是1 而且因为这是一个分类问题 我们的训练集 具有这样的特征 所有的y 不是0就是1
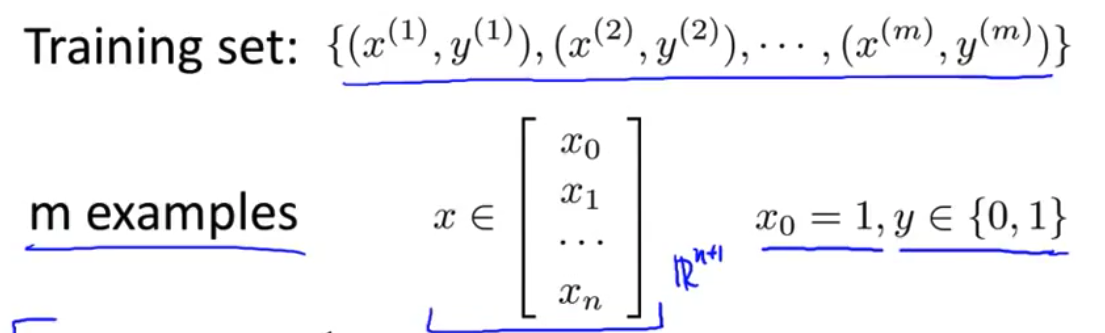
- 这是一个
假设函数它的参数是这里的这个$\theta$ 我要说的问题是 对于这个给定的训练集 我们如何选择 或者说如何拟合参数$\theta$

- 以前我们推导线性回归时 使用了这个代价函数 $J(\theta)=\frac{1}{m}\sum\limits_{i=1}^m\frac{1}{2}\left(h_\theta(x^{(i)})-y^{(i)}\right)^2$ 我把这个写成稍微有点儿不同的形式 不写原先的$\frac{1}{2m}$ 我把$\frac{1}{2}$ 放到求和符号里面了
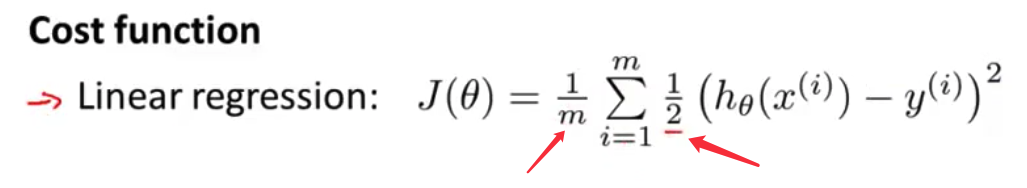
- 现在我想用另一种方法来写代价函数 去掉这个平方项 把这里写成 这样的形式 $Cost(h_\theta(x^{(i)},y^{(i)})$ 定义这个
Cost函数为$Cost(h_\theta(x^{(i)},y^{(i)})=\frac{1}{2}\left(h_\theta(x^{(i)})-y^{(i)}\right)^2$
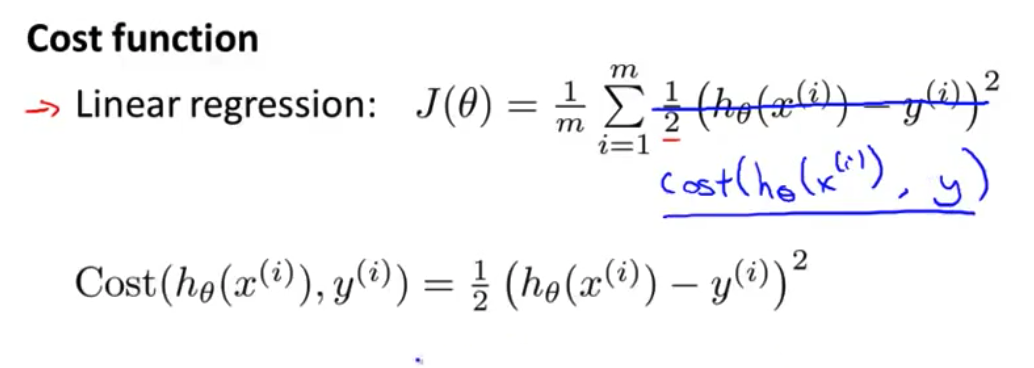
- 我们能更清楚的看到 代价函数是这个
Cost函数在训练集范围上的求和 或者说是$\frac{1}{m}$倍的 这个代价项在训练集范围上的求和 然后稍微简化一下这个式子 去掉这些上标 会显得方便一些所以直接定义 代价值$(h(x),y)$ 等于$\frac{1}{2}$倍的 这个平方根误差

- 对这个代价项的理解是这样的 这是我所期望的 我的学习算法 如果想要达到这个值 也就是这个假设$h(x)$ 所需要付出的代价 这个希望的预测值是$h(x)$ 而实际值则是$y$ 显然 在
线性回归中代价值会被定义为 1/2乘以 预测值$h$和 实际值观测的结果$y$ 的差的平方 这个代价值可以 很好地用在线性回归里

- 但是我们现在要用在逻辑回归里 如果我们可以最小化 代价函数$J$里面的这个代价值 它会工作得很好 但实际上 如果我们使用这个代价值 它会变成参数$\theta$的
非凸函数 - 我说的非凸函数是这个意思 对于这样一个代价函数$J(\theta)$ 对于
逻辑回归来说 这里的$h$函数 是非线性的 对吧? 它是等于 $\frac{1}{1+e^{-\theta^Tx}}$ 所以它是一个很复杂的非线性函数 如果对它取Sigmoid函数然后把它放到$Cost(h_\theta(x^{(i)},y^{(i)})$ 然后求它的代价值 再把它放到$J(\theta)$上 然后再画出 $J(\theta)$长什么模样 你会发现 $J(\theta)$可能是一个这样的函数 有很多局部最优值 称呼它的正式术语是 这是一个非凸函数(non-convex)
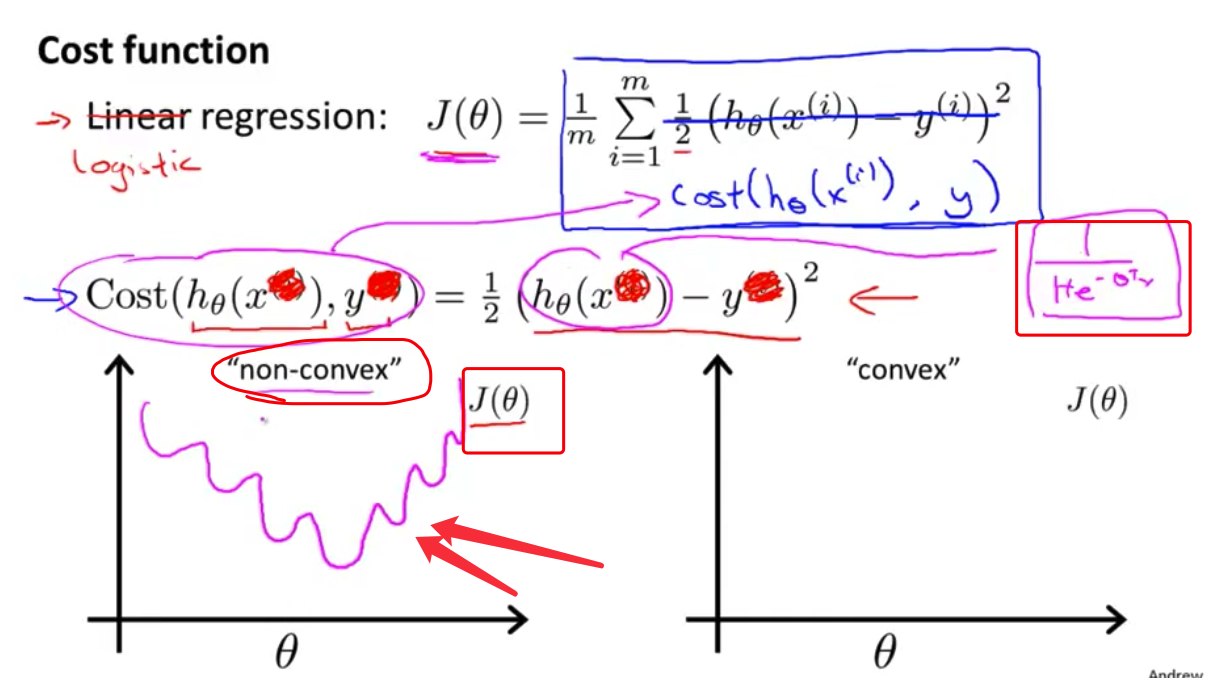
- 你大概可以发现 如果你把梯度下降法 用在一个这样的函数上 不能保证它会 收敛到全局最小值 相应地 我们希望 我们的代价函数$J(\theta)$ 是一个
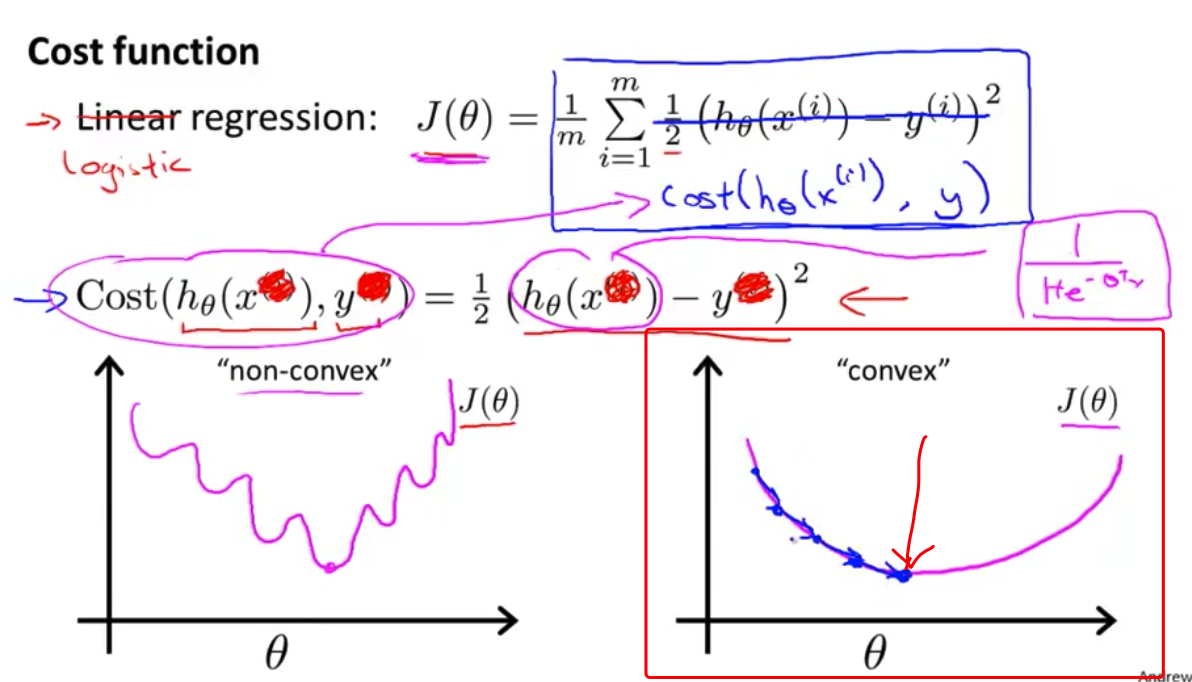
凸函数(convex)是一个单弓形函数 大概是这样 所以如果对它使用梯度下降法 我们可以保证梯度下降法 会收敛到该函数的全局最小值
- 但使用这个 平方代价函数的问题是 因为中间的这个 非常非线性的 sigmoid函数的出现 如果你要用平方函数定义它的话 导致$J(\theta)$成为 一个
非凸函数所以我们想做的是 另外找一个 不同的代价函数 它是凸函数 使得我们可以使用很好的算法 如梯度下降法 而且能保证找到全局最小值 - 下面这个代价函数便是我们要用在逻辑回归上的 我们认为 这个算法要付的代价或者惩罚 如果输出值是$h(x)$ 或者换句话说 假如说预测值$h(x)$ 是一个数 比如0.7 而实际上 真实的标签值是$y$ 那么代价值将等于 当$y=1$时 代价函数为$-log(h(x))$ 以及当$y=0$时 代价函数为$-log(1-h(x))$ 这看起来是个非常复杂的函数 但是让我们画出这个函数 可以直观地感受一下它在做什么
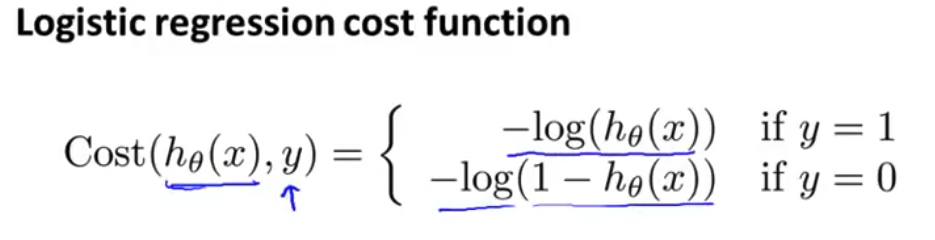
- 我们从$y=1$这个情况开始 如果$y$等于1 那么这个代价函数 是$-log(h(x))$ 如果我们要画出它 我们先将$h(x)$ 画在横坐标上 我们知道假设函数 的输出值 是在0和1之间的 对吧? 所以$h(x)$的值 在0和1之间变化 如果你画出这个代价函数的样子 你会发现它看起来是这样的
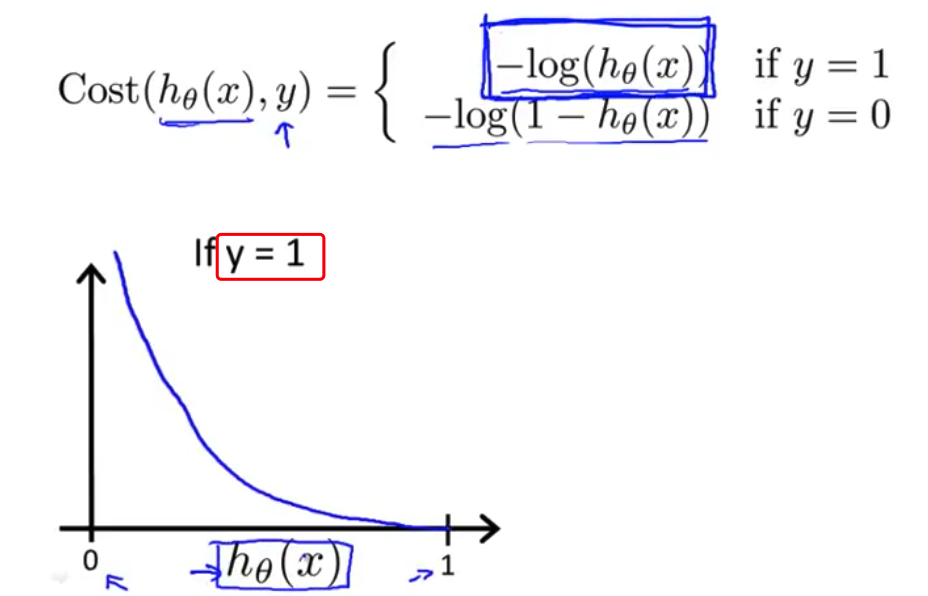
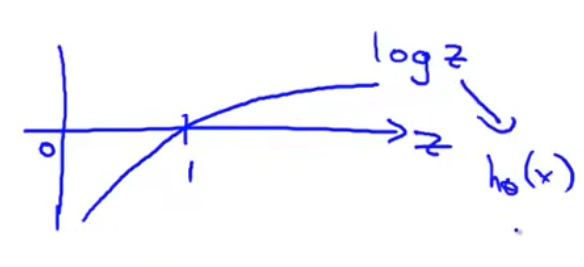
- 理解这个函数为什么是这样的一个方式是 如果你画出$log(z)$ $z$在横轴上 它看起来会是这样 它趋于负无穷 这是对数函数的样子 所以这里是0 这里是1 显然 这里的$z$ 就是代表$h(x)$的角色
- 因此 $-log(z)$看起来这样 就是翻转一下符号
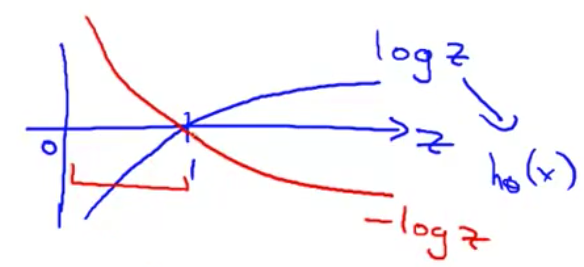
- 我们所感兴趣的是 函数在0到1 之间的这个区间 所以 忽略那些 所以只剩下 曲线的这部分 这就是左边这条曲线的样子
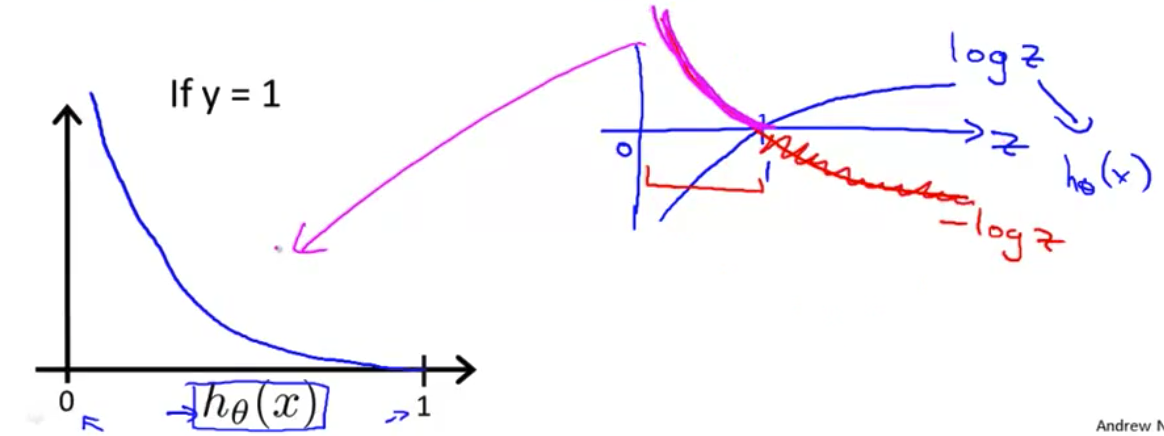
- 现在这个代价函数 有一些有趣而且很好的性质 首先 你注意到 如果$y=1$而且$h(x)=1$ 也就是说 如果假设函数$h(x)$ 刚好预测值是1 而且$y$刚好等于我预测的1 那么这个代价值等于0 而且这对应于下面这个点

- 这里我们只需要考虑 $y=1$的情况 如果$h(x)$等于1 那么代价值等于0 这是我们所希望的 因为如果我们 正确预测了输出值$y$ 那么代价值是0 但是现在 同样注意到$h(x)$趋于0时 所以 那是$h$ 当假设函数的输出趋于0时 代价值激增 并且趋于无穷
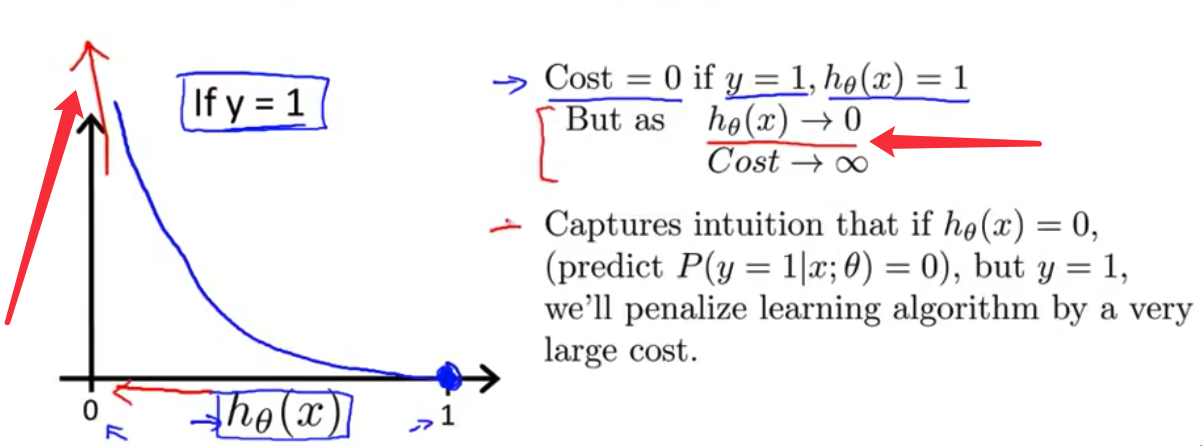
- 我们这样描述 体现出了这样一种直观的感觉 那就是如果
假设函数输出0 相当于说 我们的假设函数说 $y=1$的概率等于0 这类似于 我们对病人说 你有一个恶性肿瘤的概率 即 $y=1$的概率是0 就是说你的肿瘤 完全不可能是恶性的 然而结果是 病人的肿瘤确实是恶性的 所以 即使我们告诉他们 $y=1$发生的概率是0 这个肿瘤完全不可能是恶性的 如果我们告诉他们这个 和我们的确信程度 并且最后我们是错的 那么我们就用非常非常大的代价值 惩罚这个学习算法 它是被这样体现出来 如果$y=1$ 而$h(x)$趋于0 这个代价值趋于无穷 以上是$y=1$时的情况

- 我们再来看看 $y=0$时 代价值函数是什么样 如果$y=0$ 那么代价值是这个表达式 $-log(1-h_\theta(x))$ 如果画出函数 $-log(1-z)$ 那么你得到的 是这样 它从0到1 差不多这样

- 如果你画出 y=0情况下的代价函数 你会发现大概是这样 它现在所做的是 在$h(x)$趋于1时激增 趋于正无穷 因为它是说 如果最后发现 $y$等于0 而我们却几乎 非常肯定地预测 $y=1$的概率是1 那么我们最后就要付出非常大的代价值
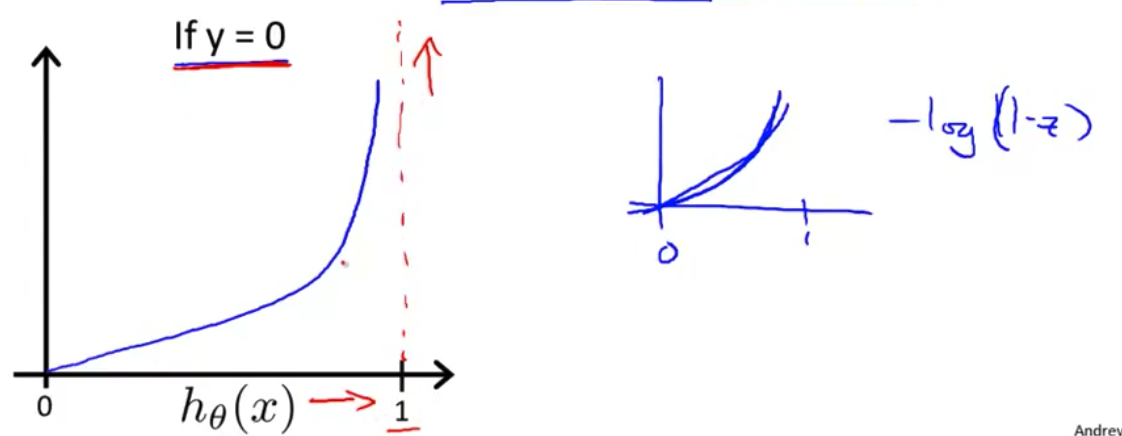
- 反过来 如果$h(x)=0$ 而且$y=0$ 那么假设函数预测对了 预测的是$y=0$ 并且y就是等于0 那么代价值函数在这点上 应该等于0
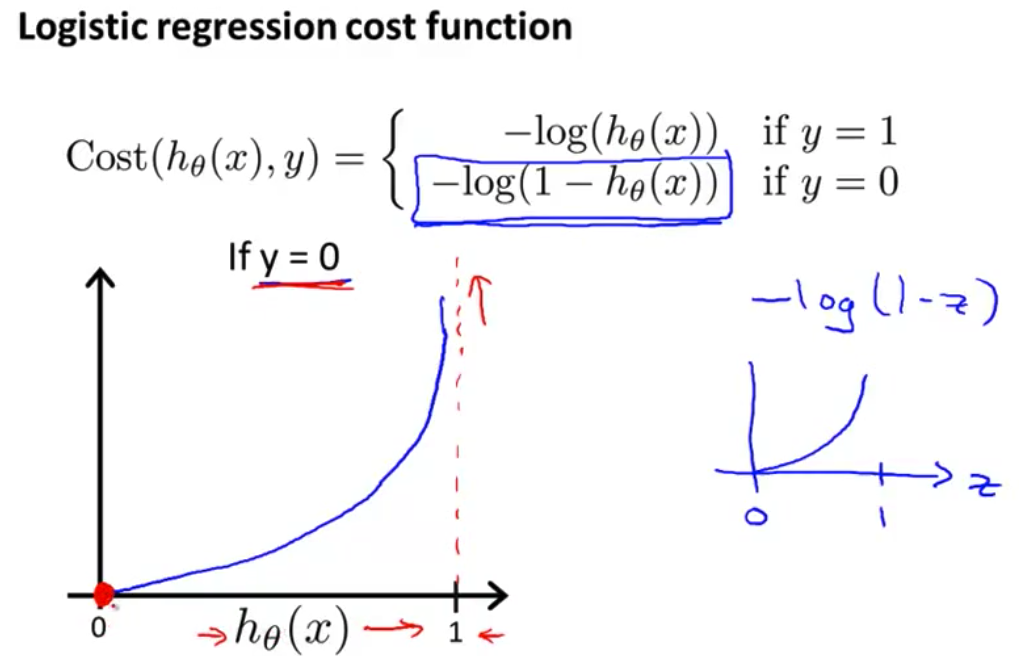
- 在这个视频中 我们定义了 单训练样本的代价函数 凸性分析的内容是超出这门课的范围的 但是可以证明 我们所选的 代价值函数 会给我们一个 凸优化问题 代价函数$J(\theta)$会是一个凸函数 并且没有局部最优值 在下一个视频中 我们会把单训练样本的 代价函数的这些理念 进一步发展 然后给出 整个训练集的代价函数的定义 我们还会找到一种 比我们目前用的 更简单的写法,基于这些推导出的结果 我们将应用梯度下降法 得到我们的逻辑回归算法
小小的总结–代价函数
在这段视频中,我们要介绍如何拟合逻辑回归模型的参数$\theta$。具体来说,我要定义用来拟合参数的优化目标或者叫代价函数,这便是监督学习问题中的逻辑回归模型的拟合问题。

对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。将其转换一下,如下图
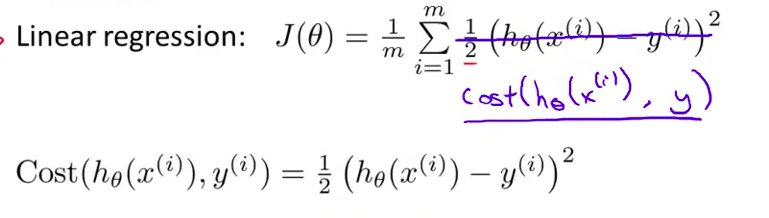
理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将${h_\theta}\left( x \right)=\frac{1}{1+{e^{-\theta^{T}}X}}$代入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convexfunction)。
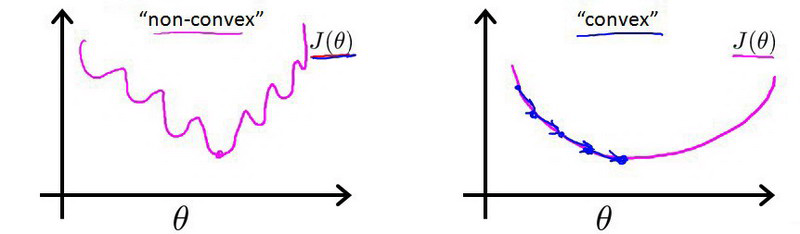
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
线性回归的代价函数为:$J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{1}{2}{{\left( {h_\theta}\left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}}$ 。
我们重新定义逻辑回归的代价函数为:$J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{{Cost}\left( {h_\theta}\left( {x}^{\left( i \right)} \right),{y}^{\left( i \right)} \right)}$,其中
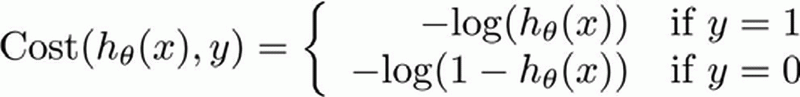
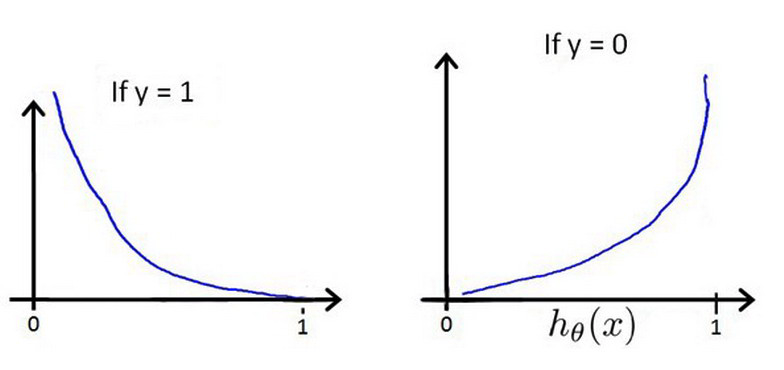
这样构建的$Cost\left( {h_\theta}\left( x \right),y \right)$函数的特点是:当实际的 $y=1$ 且${h_\theta}\left( x \right)$也为 1 时误差为 0,当 $y=1$ 但${h_\theta}\left( x \right)$不为1时误差随着${h_\theta}\left( x \right)$变小而变大;当实际的 $y=0$ 且${h_\theta}\left( x \right)$也为 0 时代价为 0,当$y=0$ 但${h_\theta}\left( x \right)$不为 0时误差随着 ${h_\theta}\left( x \right)$的变大而变大。
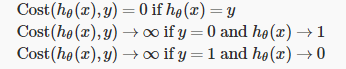
对于第一个图,我们的预测值$h_\theta(x)$与真实值$y$相同,所有cost()应该是0,满足我们的需求,之后的也一样
将构建的 $Cost\left( {h_\theta}\left( x \right),y \right)$简化如下:
$Cost\left( {h_\theta}\left( x \right),y \right)=-y\times log\left( {h_\theta}\left( x \right) \right)-(1-y)\times log\left( 1-{h_\theta}\left( x \right) \right)$
带入代价函数得到:
$J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}$即:$J\left( \theta \right)=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}$
向量化如下
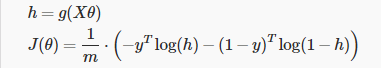
Python代码实现:
import numpy as np
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X* theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T)))
return np.sum(first - second) / (len(X))在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。算法为:
Repeat {
$\theta_j := \theta_j - \alpha \frac{\partial}{\partial\theta_j} J(\theta)$(simultaneously update all )
}
求导后得到:
Repeat {
$\theta_j := \theta_j - \alpha \frac{1}{m}\sum\limits_{i=1}^{m}{{\left( {h_\theta}\left( \mathop{x}^{\left( i \right)} \right)-\mathop{y}^{\left( i \right)} \right)}}\mathop{x}_{j}^{(i)}$(simultaneously update all )
}
向量化如下:
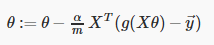
在这个视频中,我们定义了单训练样本的代价函数,凸性分析的内容是超出这门课的范围的,但是可以证明我们所选的代价值函数会给我们一个凸优化问题。代价函数J($\theta$)会是一个凸函数,并且没有局部最优值。
推导过程:
$J\left( \theta \right)=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}$考虑:
${h_\theta}\left( {{x}^{(i)}} \right)=\frac{1}{1+{{e}^{-{\theta^T}{{x}^{(i)}}}}}$则:
${{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)$ $={{y}^{(i)}}\log \left( \frac{1}{1+{{e}^{-{\theta^T}{{x}^{(i)}}}}} \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-\frac{1}{1+{{e}^{-{\theta^T}{{x}^{(i)}}}}} \right)$ $=-{{y}^{(i)}}\log \left( 1+{{e}^{-{\theta^T}{{x}^{(i)}}}} \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1+{{e}^{{\theta^T}{{x}^{(i)}}}} \right)$所以:
$\frac{\partial }{\partial {\theta_{j}}}J\left( \theta \right)=\frac{\partial }{\partial {\theta_{j}}}[-\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( 1+{{e}^{-{\theta^{T}}{{x}^{(i)}}}} \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1+{{e}^{{\theta^{T}}{{x}^{(i)}}}} \right)]}]$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\frac{-x_{j}^{(i)}{{e}^{-{\theta^{T}}{{x}^{(i)}}}}}{1+{{e}^{-{\theta^{T}}{{x}^{(i)}}}}}-\left( 1-{{y}^{(i)}} \right)\frac{x_j^{(i)}{{e}^{{\theta^T}{{x}^{(i)}}}}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}}}]$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{{y}^{(i)}}\frac{x_j^{(i)}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}}-\left( 1-{{y}^{(i)}} \right)\frac{x_j^{(i)}{{e}^{{\theta^T}{{x}^{(i)}}}}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}}]$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{{{y}^{(i)}}x_j^{(i)}-x_j^{(i)}{{e}^{{\theta^T}{{x}^{(i)}}}}+{{y}^{(i)}}x_j^{(i)}{{e}^{{\theta^T}{{x}^{(i)}}}}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}}}$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{{{y}^{(i)}}\left( 1\text{+}{{e}^{{\theta^T}{{x}^{(i)}}}} \right)-{{e}^{{\theta^T}{{x}^{(i)}}}}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}}x_j^{(i)}}$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{({{y}^{(i)}}-\frac{{{e}^{{\theta^T}{{x}^{(i)}}}}}{1+{{e}^{{\theta^T}{{x}^{(i)}}}}})x_j^{(i)}}$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{({{y}^{(i)}}-\frac{1}{1+{{e}^{-{\theta^T}{{x}^{(i)}}}}})x_j^{(i)}}$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}-{h_\theta}\left( {{x}^{(i)}} \right)]x_j^{(i)}}$ $=\frac{1}{m}\sum\limits_{i=1}^{m}{[{h_\theta}\left( {{x}^{(i)}} \right)-{{y}^{(i)}}]x_j^{(i)}}$注:虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的${h_\theta}\left( x \right)=g\left( {\theta^T}X \right)$与线性回归中不同,所以实际上是不一样的。另外,在运行梯度下降算法之前,进行特征缩放依旧是非常必要的。
一些梯度下降算法之外的选择:
除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:共轭梯度(Conjugate Gradient),局部优化法(Broyden fletcher goldfarb shann,BFGS)和有限内存局部优化法(LBFGS) fminunc是 matlab和octave 中都带的一个最小值优化函数,使用时我们需要提供代价函数和每个参数的求导,下面是 octave 中使用 fminunc 函数的代码示例:
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
options = optimset('GradObj', 'on', 'MaxIter', '100');
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);在下一个视频中,我们会把单训练样本的代价函数的这些理念进一步发展,然后给出整个训练集的代价函数的定义,我们还会找到一种比我们目前用的更简单的写法,基于这些推导出的结果,我们将应用梯度下降法得到我们的逻辑回归算法。
6.5 简化的成本函数和梯度下降
- 在这段视频中 我们将会找出 一种稍微简单一点的方法来 写代价函数 来替换我们现在用的方法 同时我们还要弄清楚 如何运用梯度下降法 来拟合出逻辑回归的参数 因此 听了这节课 你就应该知道如何 实现一个完整的逻辑回归算法
- 这就是逻辑回归的代价函数 我们的整体代价函数 不同的训练样本 假设函数 $h(x)$ 对实际值 $y^{(i)}$ 进行预测 所得到的不同误差 算出的
Cost 函数值
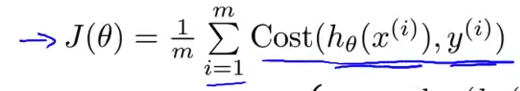
- 并且这是我们之前 算出来的一个单个样本的代价值 我只是想提醒你一下 对于分类问题 我们的训练集 甚至其他不在训练集中的样本 $y$ 的值总是等于0或1的 对吗?这就是 $y$ 的数学定义决定的
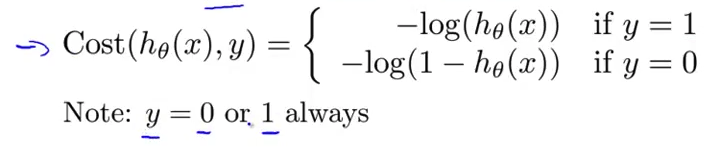
- 由于 $y$ 是0或1 我们就可以 想出一个简单的 方式来写这个代价函数 具体来说 为了避免把代价函数 写成两行 避免分成 $y=1$ 或 $y=0$ 两种情况来写 我们要用一种方法 来把这两个式子 合并成一个 这将使我们更方便地 写出代价函数 并推导出梯度下降
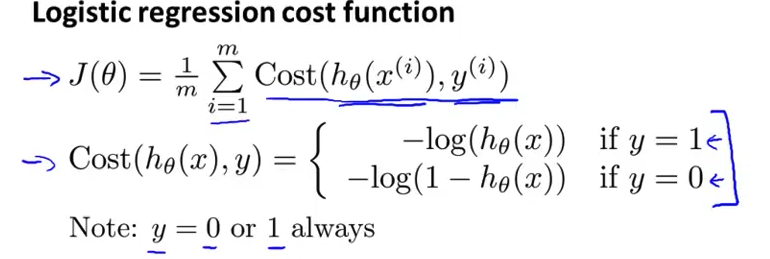
- 具体而言 我们可以如下写出代价函数 $Cost(h(x), y)$ 可以写成 以下的形式 $Cost(h_\theta(x),y)=-ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))$我马上就会给你演示 这个表达式或 等式与我们已经得出的 代价函数的表达 是完全等效的 并且更加紧凑 让我们来看看为什么会是这样

- 我们知道有两种可能情况 $y$ 必须是0或1 因此 我们假设 $y$ 等于1 那么这个Cost 值 是等于 $-1*log(h_\theta(x))-(1-1)log(1-h_\theta(x))$ 如果 y 等于1 那么 $1-y$ 就是$1-1$ 也就是0 因此第二项乘以0 就被消去了 我们只留下了 第一项 $y=1$倍的$log$ 项 $-logh_\theta(x)$ 因此就等于这个等式 而这个等式正是我们在上面未简化时 $y=1$ 的情况

- 另一种情况是 如果 $y=0$ 如果是这样的话 那么写出的 Cost 函数就是这样的 如果 $y$ 是等于0 那么第一项就为0 而$1-y$ 在$y=0$时 $1-y$就是 $1-0$ 所以 最后就等于1 这样 Cost 函数 就简化为只有这最后一项 $-log(1-h_\theta(x))$对吧? 因为第一项 在这里乘以零 所以它被消去了 所以 我们只剩下最后的 $-log(1-h_\theta(x))$ 这一项 而且这一项 就是当$y=0$时的这一项

- 因此这表明 这样定义的 Cost 函数 只是把这两个式子 写成一种更紧凑的形式 不需要分 $y=1$ 或 $y=0$ 来写 直接写在一起 只用一行来表示
- 这样我们就可以写出 逻辑回归的代价函数如下 它是这样的 就是 $\frac{1}{m}$ 乘以后面这个 Cost 函数 在这里放入之前 定义好的 Cost 函数 这个函数就完成了 我们把负号放在外面 我们为什么要把代价函数写成这种形式 似乎我们也可以选择别的方法来写代价函数 在这节课中我没有时间 来介绍有关这个问题的细节 但我可以告诉你 这个式子是从统计学中的
极大似然法得来的 估计 统计学的思路是 如何为不同的模型 有效地找出不同的参数 同时它还有一个很好的性质 它是凸的因此 这就是基本上 大部分人使用的 逻辑回归代价函数 如果我们不理解这些项 如果你不知道 什么是极大似然估计 不用担心 这里只是一个更深入 更合理的证明而已 在这节课中 我没有时间去仔细讲解

- 根据这个代价函数 为了拟合出参数 我们怎么办呢?我们要试图找尽量让 $J(\theta)$ 取得最小值的参数 $\theta$ 所以我们想要尽量减小这一项 这将我们将得到某个参数 $\theta$

- 最后 如果我们给出一个新的样本 假如某个特征 $x$ 我们可以用拟合训练样本的参数 $\theta$ 来输出对假设的预测 另外提醒你一下 我们假设的输出 实际上就是这个概率值 $p(y=1|x;\theta)$ 就是关于 $x$ 以 $\theta$ 为参数 $y=1$ 的概率 你就把这个想成我们的假设 就是估计 $y=1$ 的概率 所以 接下来要做的事情 就是弄清楚 作为一个关于 $\theta$ 的函数 如何最大限度地 最小化代价函数 $J(\theta)$ 这样我们才能为训练集拟合出参数 $\theta$

- 最小化代价函数的方法 是使用
梯度下降法(gradient descent)这是我们的代价函数
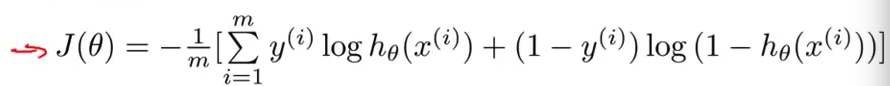
- 如果我们要最小化这个关于 $\theta$ 的函数值 这就是我们通常用的
梯度下降法的模板我们要反复更新每个参数 用这个式子来更新 就是用它自己减去 学习率 $\alpha$ 乘以后面的微分项

- 如果你知道一些微积分的知识 你可以自己动手 算一算这个微分项 $\frac{\partial}{\partial\theta_j}J(\theta)$ 看看你算出来的 跟我得到的是不是一样 即使你不知道微积分 也不用担心 如果你计算一下的话 你会得到的是这个式子 $\frac{\partial}{\partial\theta_j}J(\theta)=\frac{1}{m}\sum\limits_{i=1}^m\left(h_\theta(x^{(i)}-y^{(i)}\right)x_j^{(i)}$

- 所以你把这个偏导数项 放回到原来式子这里 我们就可以将 梯度下降算法写作如下形式

- 所以,如果你有 $n$ 个特征,也就是说:$\theta=\begin{bmatrix} \theta_0\\\ \theta_1\\\ \theta_2\\\ ...\\\ \theta_n \end{bmatrix}$,参数向量$\theta$包括${\theta_{0}}$ ${\theta_{1}}$ ${\theta_{2}}$ 一直到${\theta_{n}}$,那么你就需要用这个式子:
现在,如果你把这个更新规则和我们之前用在线性回归上的进行比较的话,你会惊讶地发现,这个式子正是我们用来做线性回归梯度下降的。那么,线性回归和逻辑回归是同一个算法吗?要回答这个问题,我们要观察逻辑回归看看发生了哪些变化。实际上,假设的定义发生了变化。
对于线性回归假设函数:${h_\theta}\left( x \right)={\theta^T}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}$ 而现在逻辑函数假设函数 ${h_\theta}\left( x \right)=\frac{1}{1+{{e}^{-{\theta^T}X}}}$ 因此,即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。

- 在先前的视频中 当我们在谈论线性回归的 梯度下降法时 我们谈到了如何监控 梯度下降法以确保其收敛 我通常也把同样的方法 用在逻辑回归中 来监测梯度下降 以确保它正常收敛 希望你自己能想清楚 如何把同样的方法 应用到逻辑函数的梯度下降中
- 当使用梯度下降法 来实现逻辑回归时 我们有这些不同的参数 θ 就是 θ0 到 θn 我们需要用这个表达式来更新这些参数 我们还可以使用 for 循环来实现 所以
for i=1 to n或者for i=1 to n+1用一个 for 循环来更新这些参数值 当然 不用 for 循环也是可以的 理想情况下 我们更提倡使用向量化的实现 因此 向量化的实现 可以把所有这些 $n$ 个 参数同时更新 一举搞定 为了检查你自己的理解 是否到位 你可以自己想想 应该怎么样实现这个 向量化的实现方法

- 好的 现在你知道如何 实现逻辑回归的梯度下降 最后还有一个 我们之前在谈线性回归时讲到的特征缩放 我们看到了特征缩放是如何 提高梯度下降的收敛速度的 这个特征缩放的方法 也适用于逻辑回归 如果你的特征范围差距很大的话 那么应用特征缩放的方法 同样也可以让逻辑回归中 梯度下降收敛更快
- 就是这样 现在你知道如何实现 逻辑回归 这是一种非常强大 甚至可能世界上使用最广泛的 一种分类算法 而现在你已经知道如何去实现它了
小小的总结–简化的成本函数和梯度下降
在这段视频中,我们将会找出一种稍微简单一点的方法来写代价函数,来替换我们现在用的方法。同时我们还要弄清楚如何运用梯度下降法,来拟合出逻辑回归的参数。因此,听了这节课,你就应该知道如何实现一个完整的逻辑回归算法。
这就是逻辑回归的代价函数:

这个式子可以合并成:
$Cost\left( {h_\theta}\left( x \right),y \right)=-y\times log\left( {h_\theta}\left( x \right) \right)-(1-y)\times log\left( 1-{h_\theta}\left( x \right) \right)$即,逻辑回归的代价函数:
$Cost\left( {h_\theta}\left( x \right),y \right)=-y\times log\left( {h_\theta}\left( x \right) \right)-(1-y)\times log\left( 1-{h_\theta}\left( x \right) \right)$ $=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}$根据这个代价函数,为了拟合出参数,该怎么做呢?我们要试图找尽量让 $J\left( \theta \right)$ 取得最小值的参数$\theta$。
$\underset{\theta}{\min }J\left( \theta \right)$所以我们想要尽量减小这一项,这将我们将得到某个参数$\theta$。
如果我们给出一个新的样本,假如某个特征 x,我们可以用拟合训练样本的参数$\theta$,来输出对假设的预测。
另外,我们假设的输出,实际上就是这个概率值:$p(y=1|x;\theta)$,就是关于 $x$以$\theta$为参数,$y=1$ 的概率,你可以认为我们的假设就是估计 $y=1$ 的概率,所以,接下来就是弄清楚如何最大限度地最小化代价函数$J\left( \theta \right)$,作为一个关于$\theta$的函数,这样我们才能为训练集拟合出参数$\theta$。
最小化代价函数的方法,是使用梯度下降法(gradient descent)。这是我们的代价函数:
$J\left( \theta \right)=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}$如果我们要最小化这个关于$\theta$的函数值,这就是我们通常用的梯度下降法的模板。

我们要反复更新每个参数,用这个式子来更新,就是用它自己减去学习率 $\alpha$ 乘以后面的微分项。求导后得到:

如果你计算一下的话,你会得到这个等式:
${\theta_j}:={\theta_j}-\alpha \frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}}){x_{j}}^{(i)}}$我把它写在这里,将后面这个式子,在 $i=1$ 到 $m$ 上求和,其实就是预测误差乘以$x_j^{(i)}$ ,所以你把这个偏导数项$\frac{\partial }{\partial {\theta_j}}J\left( \theta \right)$放回到原来式子这里,我们就可以将梯度下降算法写作如下形式:
${\theta_j}:={\theta_j}-\alpha \frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}}){x_{j}}^{(i)}}$所以,如果你有 $n$ 个特征,也就是说: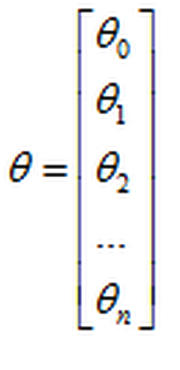 ,参数向量$\theta$包括${\theta_{0}}$ ${\theta_{1}}$ ${\theta_{2}}$ 一直到${\theta_{n}}$,那么你就需要用这个式子:
,参数向量$\theta$包括${\theta_{0}}$ ${\theta_{1}}$ ${\theta_{2}}$ 一直到${\theta_{n}}$,那么你就需要用这个式子:
现在,如果你把这个更新规则和我们之前用在线性回归上的进行比较的话,你会惊讶地发现,这个式子正是我们用来做线性回归梯度下降的。
那么,线性回归和逻辑回归是同一个算法吗?要回答这个问题,我们要观察逻辑回归看看发生了哪些变化。实际上,假设的定义发生了变化。
对于线性回归假设函数:
${h_\theta}\left( x \right)={\theta^T}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}$而现在逻辑函数假设函数:
${h_\theta}\left( x \right)=\frac{1}{1+{{e}^{-{\theta^T}X}}}$因此,即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
在先前的视频中,当我们在谈论线性回归的梯度下降法时,我们谈到了如何监控梯度下降法以确保其收敛,我通常也把同样的方法用在逻辑回归中,来监测梯度下降,以确保它正常收敛。
当使用梯度下降法来实现逻辑回归时,我们有这些不同的参数$\theta$,就是${\theta_{0}}$ ${\theta_{1}}$ ${\theta_{2}}$ 一直到${\theta_{n}}$,我们需要用这个表达式来更新这些参数。我们还可以使用 for循环来更新这些参数值,用 for i=1 to n,或者 for i=1 to n+1。当然,不用 for循环也是可以的,理想情况下,我们更提倡使用向量化的实现,可以把所有这些 n个参数同时更新。
最后还有一点,我们之前在谈线性回归时讲到的特征缩放,我们看到了特征缩放是如何提高梯度下降的收敛速度的,这个特征缩放的方法,也适用于逻辑回归。如果你的特征范围差距很大的话,那么应用特征缩放的方法,同样也可以让逻辑回归中,梯度下降收敛更快。
就是这样,现在你知道如何实现逻辑回归,这是一种非常强大,甚至可能世界上使用最广泛的一种分类算法。
6.6 高级优化
- 在上节课的视频中 用梯度下降的方法最小化 逻辑回归中代价函数 $J(\theta)$ 在这段视频中 教你们一些 高级优化算法和一些 高级的优化概念 利用这些方法 我们就能够 使通过梯度下降 进行逻辑回归的速度 大大提高 而这也将使 算法更加适合解决 大型的机器学习问题
- 比如 我们有数目庞大的特征量 现在我们换个角度 来看什么是梯度下降 我们有个代价函数 $J$ 而我们想要使其最小化 那么我们需要做的是 我们需要 编写代码 当输入参数 $\theta$ 时 它们会计算出两样东西 $J(\theta)$ 以及 $J$ 等于 0 1直到 n 时的 偏导数项 假设我们已经完成了 可以实现这两件事的代码 那么梯度下降所做的就是 反复执行这些更新 所以给出我们 用于计算这些的偏导数的代码 梯度下降法就把它插入 到这里 从而来更新参数 $\theta$

- 因此另一种考虑 梯度下降的思路是 我们需要写出代码 来计算 $J(\theta)$ 和这些偏导数 然后 把这些插入到梯度下降中 然后它就可以为我们最小化这个函数 对于梯度下降来说 我认为 从技术上讲 你实际并不需要编写代码 来计算代价函数 $J(\theta)$ 你只需要编写代码来计算导数项 但是 如果你希望 代码还要能够监控 这些 $J(\theta)$ 的收敛性 那么我们就 需要自己编写代码 来计算 代价函数和偏导数项

- 所以 在写完能够 计算这两者的代码之后 我们就可以使用梯度下降 但梯度下降并不是我们可以使用的唯一算法 还有其他一些算法 更高级 更复杂 如果我们能用 这些方法来计算 这两个项的话 那么这些算法 就是为我们优化 代价函数的不同方法

共轭梯度法BFGS (变尺度法)和L-BFGS (限制变尺度法)就是其中 一些更高级的优化算法 它们需要有一种方法来计算 $J(\theta)$ 以及需要一种方法 计算 导数项 然后使用比梯度下降更复杂 的算法来最小化代价函数这三种算法的具体细节 超出了本门课程的范畴 实际上你最后通常会 花费很多天 或几周时间研究这些算法 你可以专门学一门课来提高数值计算能力 不过让我来告诉你他们的一些特性
这三种算法有许多优点 一个是 使用这其中任何一个算法 你通常 不需要手动选择学习率$\alpha$
所以对于 这些算法的一种思路是 给出 计算导数项和代价函数的方法 你可以认为算法有一个智能的内部循环 而且 事实上 他们确实有一个智能的内部循环 称为线性搜索(line search)算法 它可以自动 尝试不同的 学习速率 $\alpha$ 并自动 选择一个好的学习速率 $\alpha$ 因此它甚至可以 为每次迭代选择不同的学习速率 那么你就不需要自己选择

这些算法实际上在做 更复杂的事情 而不仅仅是 选择一个好的学习速率 所以它们往往最终 收敛得远远快于梯度下降 不过 关于它们到底做什么的详细讨论 已经超过了本门课程的范围 实际上 我过去 使用这些算法 已经很长一段时间了 也许超过 十年了 使用得相当频繁 而直到几年前 我才真正 搞清楚 共轭梯度法 BFGS 和 L-BFGS的细节 因此 实际上完全有可能 成功使用这些算法 并应用于许多不同的学习 问题 而不需要真正理解 这些算法的内环间在做什么
如果说这些算法有缺点的话 那么我想说主要 缺点是它们比 梯度下降法复杂多了 特别是你最好 不要使用 L-BGFS BFGS这些算法 共轭梯度 L-BGFS BFGS 除非你是数值计算方面的专家
实际上 我不会建议你们编写 自己的代码来计算 数据的平方根或者 计算逆矩阵 因为对于这些算法我 还是会建议你直接使用一个软件库 所以 要求一个平方根 我们所能做的 就是调用一些 别人已经 写好用来计算数字平方根的函数 幸运的是 有 Octave 和 与它密切相关的 MATLAB 语言 我们将会用到它们 Octave 有一个非常 理想的库用于实现这些先进的优化算法 所以 如果你直接调用 它自带的库 你就能得到不错的结果
我必须指出 这些算法 实现得好或不好是有区别的 因此 如果你正在你的 机器学习程序中使用一种不同的语言 比如如果你正在使用 C C + + Java 等等 你 可能会想尝试一些 不同的库 以确保你找到一个 能很好实现这些算法的库 因为 在 L-BFGS 或者等高线梯度的 实现上 表现得好与不太好 是有差别的
因此现在让我们来说明 如何使用这些算法 我打算举一个例子 比方说 你有一个 含两个参数的问题 这两个参数是 $\theta_1$ 和 $\theta_2$ 那么你的成本函数 $J(\theta)$ 等于 $\theta_1$ 减去5的平方 再加上 $\theta_2$减5的平方 因此 通过这个代价函数 你可以得到 $\theta_1$ 和 $\theta_2$ 的值 如果你将 $J(\theta)$ 最小化的话 那么它的最小值 将是 $\theta_1$ 等于5 $\theta_2$ 等于5
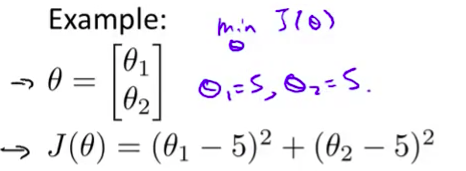
- 我知道你们当中 有些人比别人微积分更好 但是你应该知道代价函数 $J$ 的导数 推出来就是这两个表达式 我已经写在这儿了
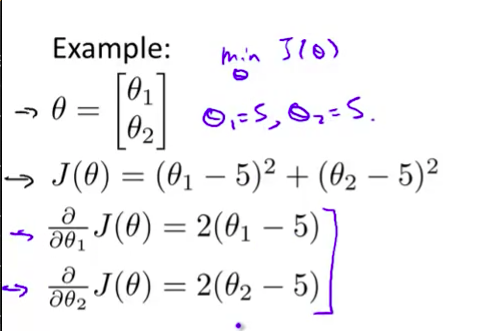
- 那么你就可以应用 高级优化算法里的一个 来最小化代价函数 $J$ 所以 如果我们 不知道最小值 是5 5 但你想要 代价函数找到这个最小值 是用比如 梯度下降这些算法 但最好是用 比它更高级的算法 你要做的就是运行一个 像这样的 Octave 函数

- 那么我们 运行一个函数 比如 costFunction 这个函数的作用就是 它会返回两个值 第一个是 jVal 它是 我们计算的代价函数 J 所以说 jVal 等于 theta(1) 减5的平方加 theta(2) 减5的平方 这样就计算出这个代价函数函数返回的第二个值是 梯度值 梯度值应该是 一个2×1的向量 梯度向量的两个元素 对应 这里的两个偏导数项

- 运行这个 costFunction 函数后 你就可以 调用高级的优化函数 这个函数叫
fminunc它表示 Octave 里无约束最小化函数

- 调用它的方式如下 你要设置几个 options 这个 options 变量 作为一个数据结构可以存储你想要的 options 所以 GradObj 和 On 这里设置梯度目标参数为打开(on) 这意味着你现在确实要给这个算法提供一个梯度 然后设置最大 迭代次数 比方说 100 我们给出一个 $\theta$ 的猜测初始值 它是一个2×1的向量 那么这个命令就调用 fminunc 这个@符号表示 指向我们刚刚定义的 costFunction 函数的指针 如果你调用它 它就会 使用众多高级优化算法中的一个 当然你也可以把它当成梯度下降 只不过它能自动选择 学习速率α 你不需要自己来做 然后它会尝试 使用这些高级的优化算法 就像加强版的梯度下降法 为你找到最佳的 θ 值

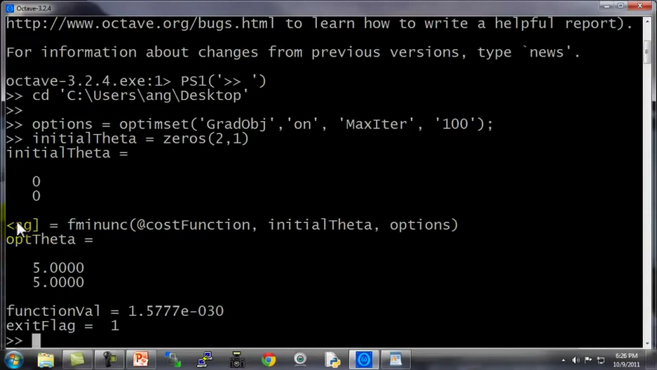
- 让我告诉你它在 Octave 里什么样 所以我写了这个关于theta的 的 costFunction 函数 跟前面幻灯片中一样 它计算出代价函数 jval 以及梯度 gradient gradient 有两个元素 是代价函数对于 theta(1) 和 theta(2) 这两个参数的 偏导数

- 现在 让我们切换到Octave窗口 我把刚刚的命令敲进去
options = optimset这是 在我的优化算法的 options上 设置参数 的记号 这样就是100 次迭代 我现在要给我的算法提供梯度值 设置 theta 的初始值是一个2×1的零向量 这是我猜测的 theta 初始值 现在我就可以 写出三个返回值[optTheta, functionVal, exitFlag]等于 指向代价函数的指针 @costFunction 我猜测的初始值 initialTheta 还有options 如果我敲回车 这个就会运行优化算法
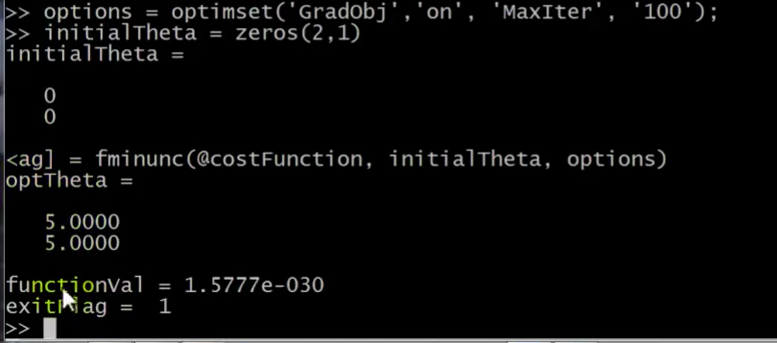
它很快返回值 这个格式很有意思 因为我的代码 是被缠住了 所以这个有点意思 完全是因为我的命令行被绕住了 不过这里只是 数字上的一些问题 把它看成是加强版梯度下降 它们找到 theta 的最优值 是 theta(1) 为5 theta(2) 也为5 这正是我们希望的 functionVal 的值 实际上是10的-30次幂 所以 这基本上就是0 这也是我们所希望的 exitFlag为1 这说明它的状态 是已经收敛了的 你也可以运行 help fminunc 命令 去查阅相关资料 以理解 exitFlag 的作用 exitFlag可以让你确定该算法是否已经收敛 这就是在 Octave 里运行这些算法的过程
哦对了 这里我得指出 用 Octave 运行的时候 向量θ的值 θ的参数向量 必须是 d 维的 d 大于等于2 所以 θ 仅仅是一个实数 因此如果它不是 一个至少二维的向量 或高于二维的向量 fminunc 就可能无法运算 因此如果你有一个 一维的函数需要优化 一维的函数需要优化 你可以查找 Octave 里 fminuc 函数的资料 来得到更多的细节 来得到更多的细节
这就是我们如何优化 一个例子的过程 这是一个 简单的二次代价函数 我们如果把它应用到逻辑回归中呢
在逻辑回归中 我们有 一个参数向量 theta 我要混合使用 Octave 记号和数学符号 我希望这个写法很明确 我们的参数 theta 由 $\theta_0$到 $\theta_n$ 组成 由 $\theta_0$到 $\theta_n$ 组成 因为在 Octave 的标号中 向量的标号是从1开始的 在 Octave 里 $\theta_0$实际上 写成 theta(1) 因此用 theta(1) 表示第一个参数 $\theta_0$ 然后有 theta(2) 接下来写到 theta(n+1) 对吧 这是因为 Octave 的记号 是向量从1开始的 而不是从0开始
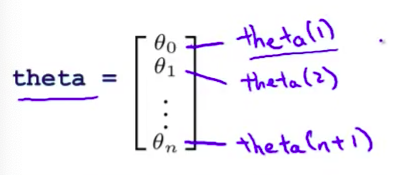
- 因此 我们需要 做的是写一个 costFunction 函数 它为 逻辑回归求得代价函数 具体点说 costFunction 函数 需要返回 jVal 值 因此需要一些代码 来计算 J(θ) 我们也需要给出梯度值 gradient 那么 gradient(1) 对应用来计算代价函数 关于 θ0 的偏导数 接下去关于 θ1 的偏导数 依此类推 再次强调 这 是gradient(1) gradient(2) 等等 而不是gradient(0) gradient(1) 因为 Octave 的标号 是从1开始 而不是从0开始的

我希望你们从这个幻灯片中 学到的主要内容是 你所要做的是 写一个函数 它能返回代价函数值 以及梯度值 因此要把这个 应用到逻辑回归 或者甚至线性回归中 你也可以把这些优化算法用于线性回归 你需要做的就是输入 合适的代码来计算 这里的这些东西 现在你已经知道如何使用这些高级的优化算法 有了这些算法 你就可以使用一个 复杂的优化库 它让算法使用起来更模糊一点 more opaque and so 因此也许稍微有点难调试 不过由于这些算法的运行速度 通常远远超过梯度下降 因此当我有一个很大的 机器学习问题时 我会选择这些高级算法 而不是梯度下降 有了这些概念 你就应该能将逻辑回归 和线性回归应用于 更大的问题中 这就是高级优化的概念
在下一个视频 也就是逻辑回归这一部分的最后一个视频中 我想要告诉你如何 修改你已经知道的逻辑回归算法 然后使它在多类别分类问题中 也能正常运行
小小的总结–高级优化
在上一个视频中,我们讨论了用梯度下降的方法最小化逻辑回归中代价函数$J\left( \theta \right)$。在本次视频中,我会教你们一些高级优化算法和一些高级的优化概念,利用这些方法,我们就能够使通过梯度下降,进行逻辑回归的速度大大提高,而这也将使算法更加适合解决大型的机器学习问题,比如,我们有数目庞大的特征量。
现在我们换个角度来看什么是梯度下降,我们有个代价函数$J\left( \theta \right)$,而我们想要使其最小化,那么我们需要做的是编写代码,当输入参数 $\theta$ 时,它们会计算出两样东西:$J\left( \theta \right)$ 以及$J$ 等于 0、1直到 $n$ 时的偏导数项。

假设我们已经完成了可以实现这两件事的代码,那么梯度下降所做的就是反复执行这些更新。
另一种考虑梯度下降的思路是:我们需要写出代码来计算$J\left( \theta \right)$ 和这些偏导数,然后把这些插入到梯度下降中,然后它就可以为我们最小化这个函数。
对于梯度下降来说,我认为从技术上讲,你实际并不需要编写代码来计算代价函数$J\left( \theta \right)$。你只需要编写代码来计算导数项,但是,如果你希望代码还要能够监控这些$J\left( \theta \right)$ 的收敛性,那么我们就需要自己编写代码来计算代价函数$J(\theta)$和偏导数项$\frac{\partial }{\partial {\theta_j}}J\left( \theta \right)$。所以,在写完能够计算这两者的代码之后,我们就可以使用梯度下降。
然而梯度下降并不是我们可以使用的唯一算法,还有其他一些算法,更高级、更复杂。如果我们能用这些方法来计算代价函数$J\left( \theta \right)$和偏导数项$\frac{\partial }{\partial {\theta_j}}J\left( \theta \right)$两个项的话,那么这些算法就是为我们优化代价函数的不同方法,共轭梯度法 BFGS (变尺度法) 和L-BFGS (限制变尺度法) 就是其中一些更高级的优化算法,它们需要有一种方法来计算 $J\left( \theta \right)$,以及需要一种方法计算导数项,然后使用比梯度下降更复杂的算法来最小化代价函数。这三种算法的具体细节超出了本门课程的范畴。实际上你最后通常会花费很多天,或几周时间研究这些算法,你可以专门学一门课来提高数值计算能力,不过让我来告诉你他们的一些特性:
这三种算法有许多优点:
一个是使用这其中任何一个算法,你通常不需要手动选择学习率 $\alpha$,所以对于这些算法的一种思路是,给出计算导数项和代价函数的方法,你可以认为算法有一个智能的内部循环,而且,事实上,他们确实有一个智能的内部循环,称为线性搜索(line search)算法,它可以自动尝试不同的学习速率 $\alpha$,并自动选择一个好的学习速率 $\alpha$,因此它甚至可以为每次迭代选择不同的学习速率,那么你就不需要自己选择。这些算法实际上在做更复杂的事情,而不仅仅是选择一个好的学习率,所以它们往往最终收敛得远远快于梯度下降,这些算法实际上在做更复杂的事情,不仅仅是选择一个好的学习速率,所以它们往往最终比梯度下降收敛得快多了,不过关于它们到底做什么的详细讨论,已经超过了本门课程的范围。
实际上,我过去使用这些算法已经很长一段时间了,也许超过十年了,使用得相当频繁,而直到几年前我才真正搞清楚共轭梯度法 BFGS 和 L-BFGS的细节。
我们实际上完全有可能成功使用这些算法,并应用于许多不同的学习问题,而不需要真正理解这些算法的内环间在做什么,如果说这些算法有缺点的话,那么我想说主要缺点是它们比梯度下降法复杂多了,特别是你最好不要使用 L-BGFS、BFGS这些算法,除非你是数值计算方面的专家。实际上,我不会建议你们编写自己的代码来计算数据的平方根,或者计算逆矩阵,因为对于这些算法,我还是会建议你直接使用一个软件库,比如说,要求一个平方根,我们所能做的就是调用一些别人已经写好用来计算数字平方根的函数。幸运的是现在我们有Octave 和与它密切相关的 MATLAB 语言可以使用。
Octave 有一个非常理想的库用于实现这些先进的优化算法,所以,如果你直接调用它自带的库,你就能得到不错的结果。我必须指出这些算法实现得好或不好是有区别的,因此,如果你正在你的机器学习程序中使用一种不同的语言,比如如果你正在使用C、C++、Java等等,你可能会想尝试一些不同的库,以确保你找到一个能很好实现这些算法的库。因为在L-BFGS或者等高线梯度的实现上,表现得好与不太好是有差别的,因此现在让我们来说明:如何使用这些算法:
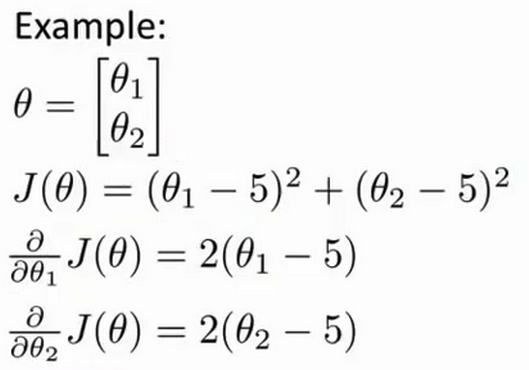
比方说,你有一个含两个参数的问题,这两个参数是${\theta_{0}}$和${\theta_{1}}$,因此,通过这个代价函数,你可以得到${\theta_{1}}$和 ${\theta_{2}}$的值,如果你将$J\left( \theta \right)$ 最小化的话,那么它的最小值将是${\theta_{1}}$等于5 ,${\theta_{2}}$等于5。代价函数$J\left( \theta \right)$的导数推出来就是这两个表达式:
$\frac{\partial }{\partial {{\theta }_{1}}}J(\theta)=2({{\theta }_{1}}-5)$ $\frac{\partial }{\partial {{\theta }_{2}}}J(\theta)=2({{\theta }_{2}}-5)$如果我们不知道最小值,但你想要代价函数找到这个最小值,是用比如梯度下降这些算法,但最好是用比它更高级的算法,你要做的就是运行一个像这样的Octave 函数:
function [jVal, gradient]=costFunction(theta)
% jVal是代价函数
jVal=(theta(1)-5)^2+(theta(2)-5)^2;
gradient=zeros(2,1);
gradient(1)=2*(theta(1)-5);
gradient(2)=2*(theta(2)-5);
end这样就计算出这个代价函数,函数返回的第二个值是梯度值,梯度值应该是一个2×1的向量,梯度向量的两个元素对应这里的两个偏导数项,运行这个costFunction 函数后,你就可以调用高级的优化函数,这个函数叫fminunc,它表示Octave 里无约束最小化函数。调用它的方式如下:
% GradObj on:表示要传入一个梯度
% MaxIter 100:表示最大迭代次数是100
options=optimset('GradObj','on','MaxIter',100);
% 这里是theta的猜测初始值
initialTheta=zeros(2,1);
% optTheta:最小化代价函数的theta
% functionVal:用了optTheta后,代价函数的值
% exitFlag:如果是1表示已经收敛
[optTheta, functionVal, exitFlag]=fminunc(@costFunction, initialTheta, options);你要设置几个options,这个 options 变量作为一个数据结构可以存储你想要的options,所以GradObj 和On,这里设置梯度目标参数为打开(on),这意味着你现在确实要给这个算法提供一个梯度,然后设置最大迭代次数,比方说100,我们给出一个$\theta$ 的猜测初始值,它是一个2×1的向量,那么这个命令就调用fminunc,这个@符号表示指向我们刚刚定义的costFunction 函数的指针。如果你调用它,它就会使用众多高级优化算法中的一个,当然你也可以把它当成梯度下降,只不过它能自动选择学习速率$\alpha$,你不需要自己来做。然后它会尝试使用这些高级的优化算法,就像加强版的梯度下降法,为你找到最佳的${\theta}$值。
让我告诉你它在 Octave 里什么样:
所以我写了这个关于theta的 costFunction 函数,它计算出代价函数 jval以及梯度gradient,gradient 有两个元素,是代价函数对于theta(1) 和 theta(2)这两个参数的偏导数。
注意:theta至少是一个二维向量
我希望你们从这个幻灯片中学到的主要内容是:写一个函数,它能返回代价函数值、梯度值,因此要把这个应用到逻辑回归,或者甚至线性回归中,你也可以把这些优化算法用于线性回归,你需要做的就是输入合适的代码来计算这里的这些东西。

现在你已经知道如何使用这些高级的优化算法,有了这些算法,你就可以使用一个复杂的优化库,它让算法使用起来更模糊一点。因此也许稍微有点难调试,不过由于这些算法的运行速度通常远远超过梯度下降。
所以当我有一个很大的机器学习问题时,我会选择这些高级算法,而不是梯度下降。有了这些概念,你就应该能将逻辑回归和线性回归应用于更大的问题中,这就是高级优化的概念。
在下一个视频,我想要告诉你如何修改你已经知道的逻辑回归算法,然后使它在多类别分类问题中也能正常运行。
6.7 多类别分类:一对多
在本节视频中 我们将谈到如何使用
逻辑回归 (logistic regression)来解决多类别分类问题 具体来说 我想通过一个叫做"一对多" (one-vs-all)的分类算法 让你了解什么是多类别分类问题先看这样一些例子 假如说你现在需要 一个学习算法 能自动地 将邮件归类到不同的文件夹里 或者说可以自动地加上标签 那么 你也许需要一些不同的文件夹 或者不同的标签来完成这件事 来区分开来自工作的邮件、来自朋友的邮件 来自家人的邮件或者是有关兴趣爱好的邮件 那么 我们就有了 这样一个分类问题 其类别有四个 分别用y=1、y=2、y=3、 y=4 来代表

- 另一个例子是有关药物诊断的 如果一个病人 因为鼻塞 来到你的诊所 他可能并没有生病 用 y=1 这个类别来代表 或者患了感冒 用 y=2 来代表 或者得了流感 y=3
- 第三个例子 也是最后一个例子 如果你正在做有关 天气的机器学习分类问题 那么你可能想要区分 哪些天是晴天、多云、雨天、 或者下雪天 对上述所有的例子 y 可以取 一个很小的数值 一个相对”谨慎”的数值 比如1到3、1到4或者其它数值 以上说的都是多类分类问题

顺便一提的是 对于下标是 0 1 2 3 还是 1 2 3 4 都不重要 我更喜欢将分类 从 1 开始标而不是 0 其实怎样标注都不会影响最后的结果
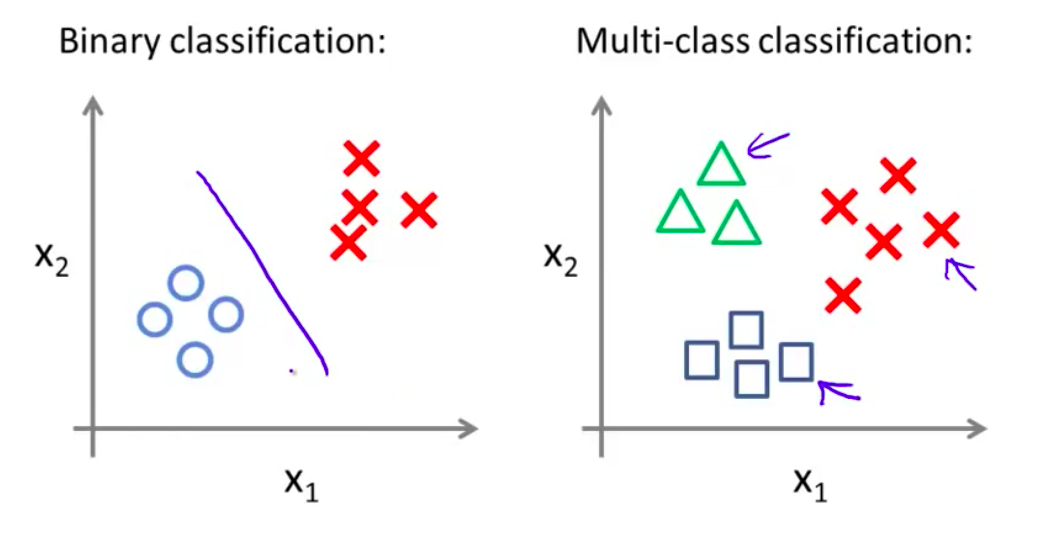
然而对于之前的一个 二元分类问题 我们的数据看起来可能是像左边这样 对于一个多类分类问题 我们的数据集 或许看起来像右边这样 我用三种不同的符号来代表三个类别 问题就是 给出三个类型的数据集 这是一个类别中的样本 而这个样本是属于 另一个类别 而这个样本属于第三个类别 我们如何得到一个学习算法来进行分类呢? 我们现在已经知道如何 进行二元分类 可以使用逻辑斯特回归 对于直线或许你也知道 可以将数据集一分为二为正类和负类 用一对多的 分类思想 我们可以 将其用在多类分类问题上
- 下面将介绍如何进行一对多的分类工作 有时这个方法也被称为”
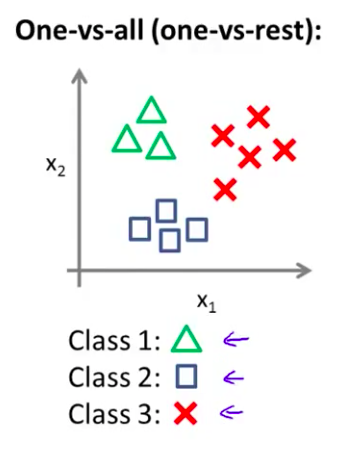
一对余(one versus rest)“方法 现在我们有一个训练集 好比左边表示的 有三个类别 我们用三角形表示 y=1 方框表示 y=2 叉叉表示 y=3
- 我们下面要做的就是 使用一个训练集 将其分成三个二元分类问题 所以我将它分成三个 二元分类问题 我们先从用三角形代表的类别1开始 实际上我们可以创建一个 新的”伪”训练集 类型2和类型3 定为负类 类型1 设定为正类 我们创建一个新的 训练集 如右侧所示的那样 我们要拟合出一个合适的分类器 我们称其为 h 下标 θ 上标(1) (x) 这里的三角形是正样本 而圆形代表负样本 可以这样想 设置三角形的值为1 圆形的值为0 下面我们来训练一个标准的 逻辑回归分类器 这样我们就得到一个正边界 对吧? 这里上标(1)表示类别1 我们可以像这样对三角形类别这么做
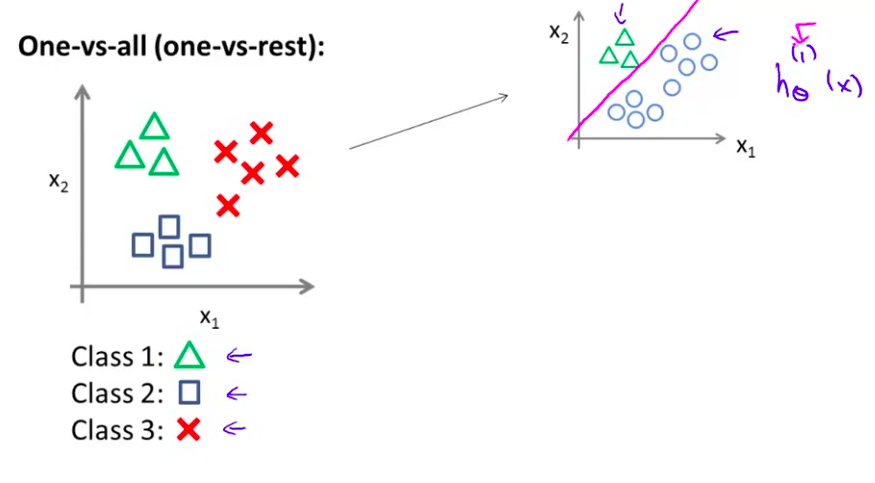
- 下面 我们将为类别2做同样的工作 取这些方块样本 然后将这些方块 作为正样本 设其它的为三角形和叉形类别为负样本 这样我们找到第二个合适的逻辑回归分类器 我们称为 h 下标 θ 上标(2) (x) 其中上标(2)表示 是类别2 所以我们做的就是 把方块类当做正样本 我们可能便会得到这样的一个分类器
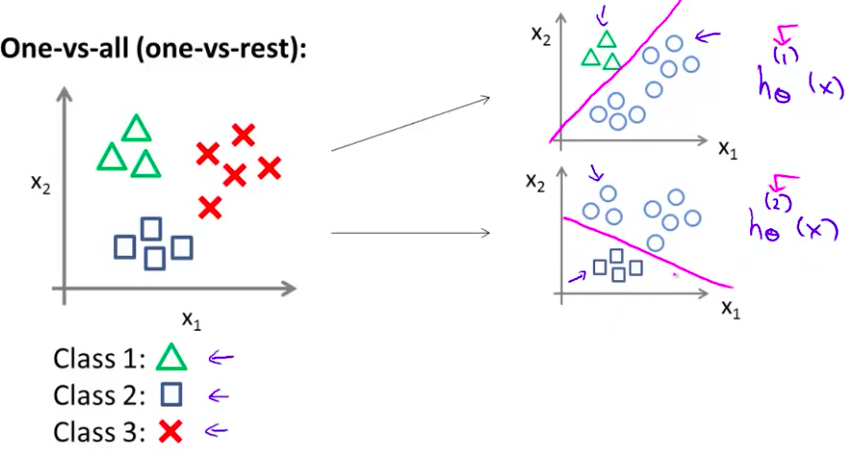
- 最后 同样地 我们对第三个类别采用同样的方法 并找出 第三个分类器 h 下标 θ 上标(3) (x)
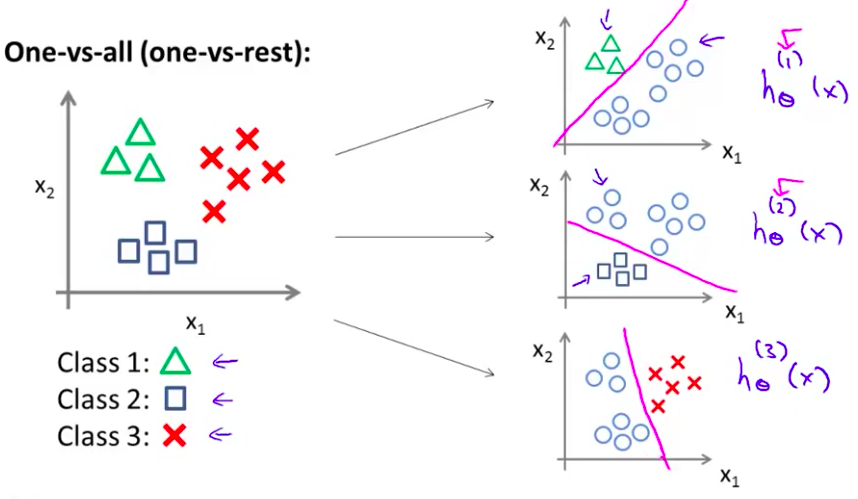
- 或许这么做 可以给出一个像这样的 判别边界 或者说分类器 能这样分开正负样本 总而言之 我们已经拟合出三个分类器 对于 i 等于1、2、3 我们都找到了一个分类器 $h^{(i)}_\theta(x)$ 通过这样来尝试 估计出 给出 x 和 θ 时 y的值等于 i 的概率 对么?
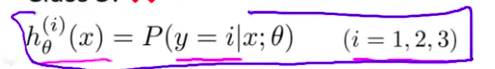
- 在一开始 对于第一个在这里的 分类器 完成了对三角形的识别 把三角形当做是正类别 所以 $h^{(1)}$ 实际上是在计算 给定x 以 $\theta$ 为参数时 y的值为1的 概率是多少
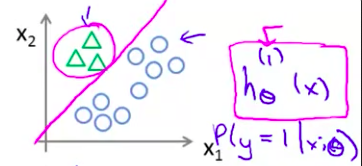
同样地 这个也是这么处理 矩形类型当做一个正类别 同样地 可以计算出 y=2 的概率和其它的概率值来 现在我们便有了三个分类器 且每个分类器都作为其中一种情况进行训练
总之 我们已经把要做的做完了 现在要做的就是训练这个 逻辑回归分类器 $h^{(i)}_\theta$ 其中 $i$ 对应每一个可能的 $y=i$

- 最后 为了做出预测 我们给出输入一个新的 x 值 用这个做预测 我们要做的 就是 在我们三个分类器 里面输入 x 然后 我们选择一个让 h 最大的 i 你现在知道了 基本的挑选分类器的方法 选择出哪一个分类器是 可信度最高效果最好的 那么就可认为得到一个正确的分类 无论i值是多少 我们都有最高的概率值 我们预测 y 就是那个值

- 这就是多类别分类问题 以及一对多的方法 通过这个小方法 你现在也可以将 逻辑回归分类器 用在多类分类的问题上
小小的总结–一对多
在本节视频中,我们将谈到如何使用逻辑回归 (logistic regression)来解决多类别分类问题,具体来说,我想通过一个叫做"一对多" (one-vs-all) 的分类算法。
先看这样一些例子。
第一个例子:假如说你现在需要一个学习算法能自动地将邮件归类到不同的文件夹里,或者说可以自动地加上标签,那么,你也许需要一些不同的文件夹,或者不同的标签来完成这件事,来区分开来自工作的邮件、来自朋友的邮件、来自家人的邮件或者是有关兴趣爱好的邮件,那么,我们就有了这样一个分类问题:其类别有四个,分别用$y=1$、$y=2$、$y=3$、$y=4$ 来代表。

第二个例子是有关药物诊断的,如果一个病人因为鼻塞来到你的诊所,他可能并没有生病,用 $y=1$ 这个类别来代表;或者患了感冒,用 $y=2$ 来代表;或者得了流感用$y=3$来代表。

第三个例子:如果你正在做有关天气的机器学习分类问题,那么你可能想要区分哪些天是晴天、多云、雨天、或者下雪天,对上述所有的例子,$y$ 可以取一个很小的数值,一个相对”谨慎”的数值,比如1 到3、1到4或者其它数值,以上说的都是多类分类问题,顺便一提的是,对于下标是0 1 2 3,还是 1 2 3 4 都不重要,我更喜欢将分类从 1 开始标而不是0,其实怎样标注都不会影响最后的结果。

然而对于之前的一个,二元分类问题,我们的数据看起来可能是像这样:
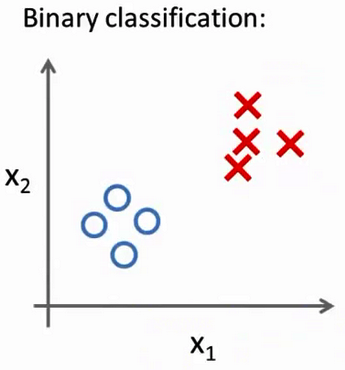
对于一个多类分类问题,我们的数据集或许看起来像这样:
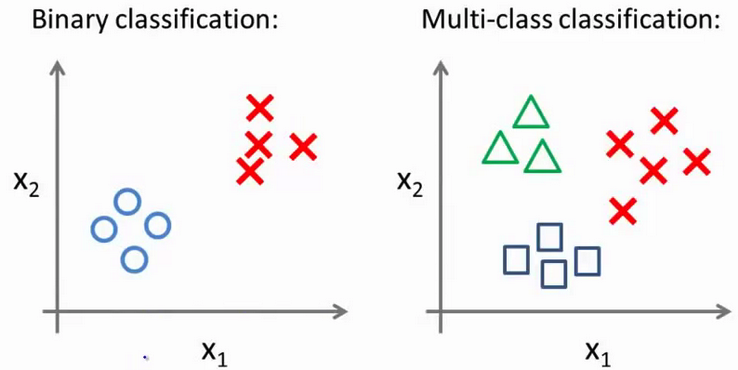
我用三种不同的符号来代表三个类别,问题就是给出三个类型的数据集,我们如何得到一个学习算法来进行分类呢?
我们现在已经知道如何进行二元分类,可以使用逻辑回归,对于直线或许你也知道,可以将数据集一分为二为正类和负类。用一对多的分类思想,我们可以将其用在多类分类问题上。
下面将介绍如何进行一对多的分类工作,有时这个方法也被称为”一对余”方法。
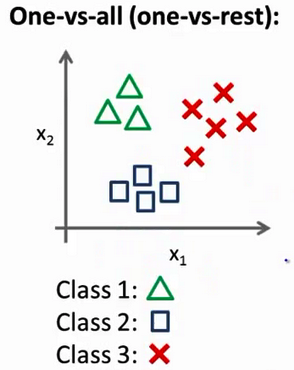
现在我们有一个训练集,好比上图表示的有三个类别,我们用三角形表示 $y=1$,方框表示$y=2$,叉叉表示 $y=3$。我们下面要做的就是使用一个训练集,将其分成三个二元分类问题。
我们先从用三角形代表的类别1开始,实际上我们可以创建一个,新的"伪"训练集,类型2和类型3定为负类,类型1设定为正类,我们创建一个新的训练集,如下图所示的那样,我们要拟合出一个合适的分类器。
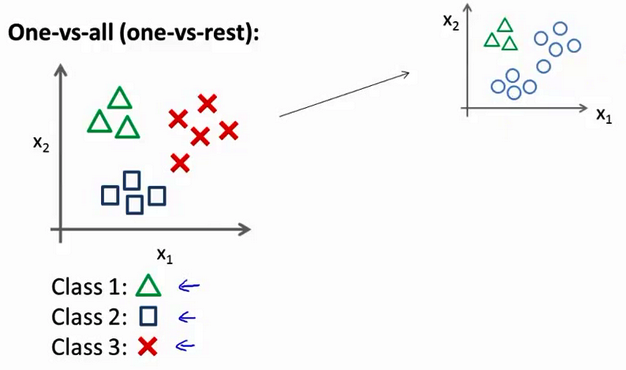
这里的三角形是正样本,而圆形代表负样本。可以这样想,设置三角形的值为1,圆形的值为0,下面我们来训练一个标准的逻辑回归分类器,这样我们就得到一个正边界。
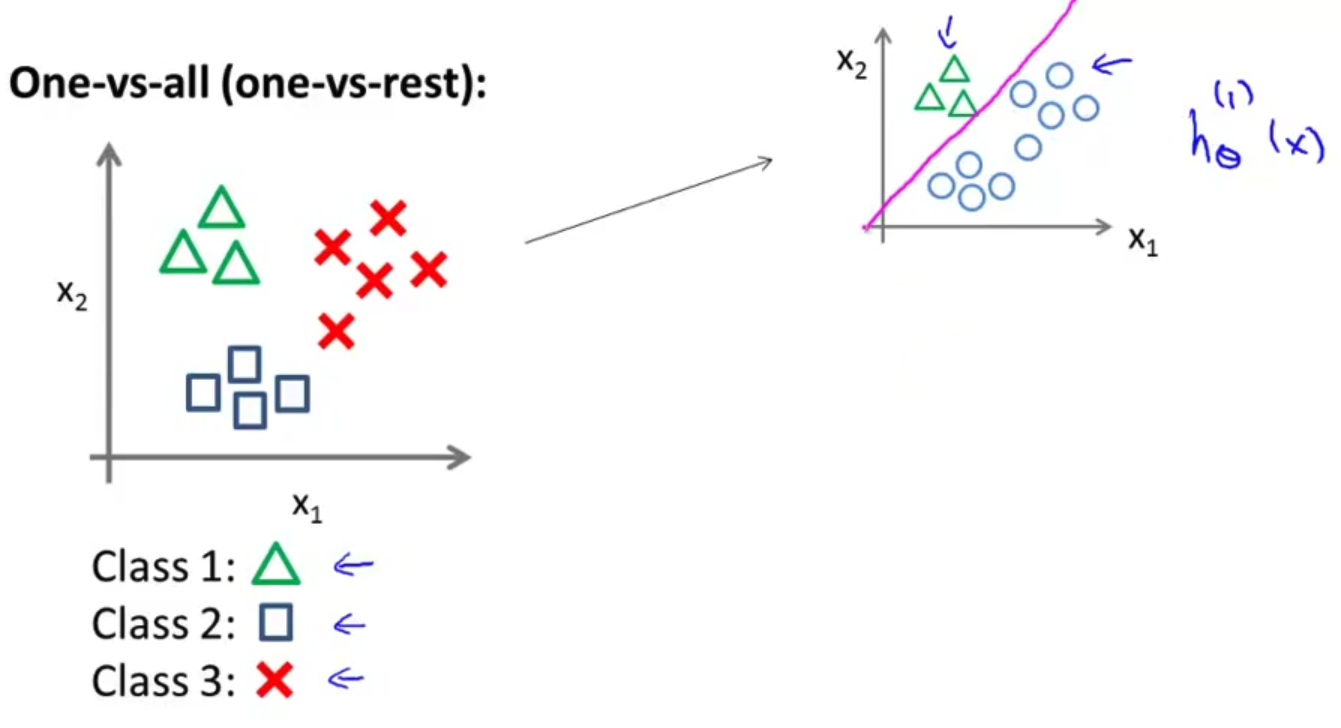
为了能实现这样的转变,我们将多个类中的一个类标记为正向类($y=1$),然后将其他所有类都标记为负向类,这个模型记作$h_\theta^{\left( 1 \right)}\left( x \right)$。接着,类似地第我们选择另一个类标记为正向类(y=2),再将其它类都标记为负向类,将这个模型记作 $h_\theta^{\left( 2 \right)}\left( x \right)$,依此类推。
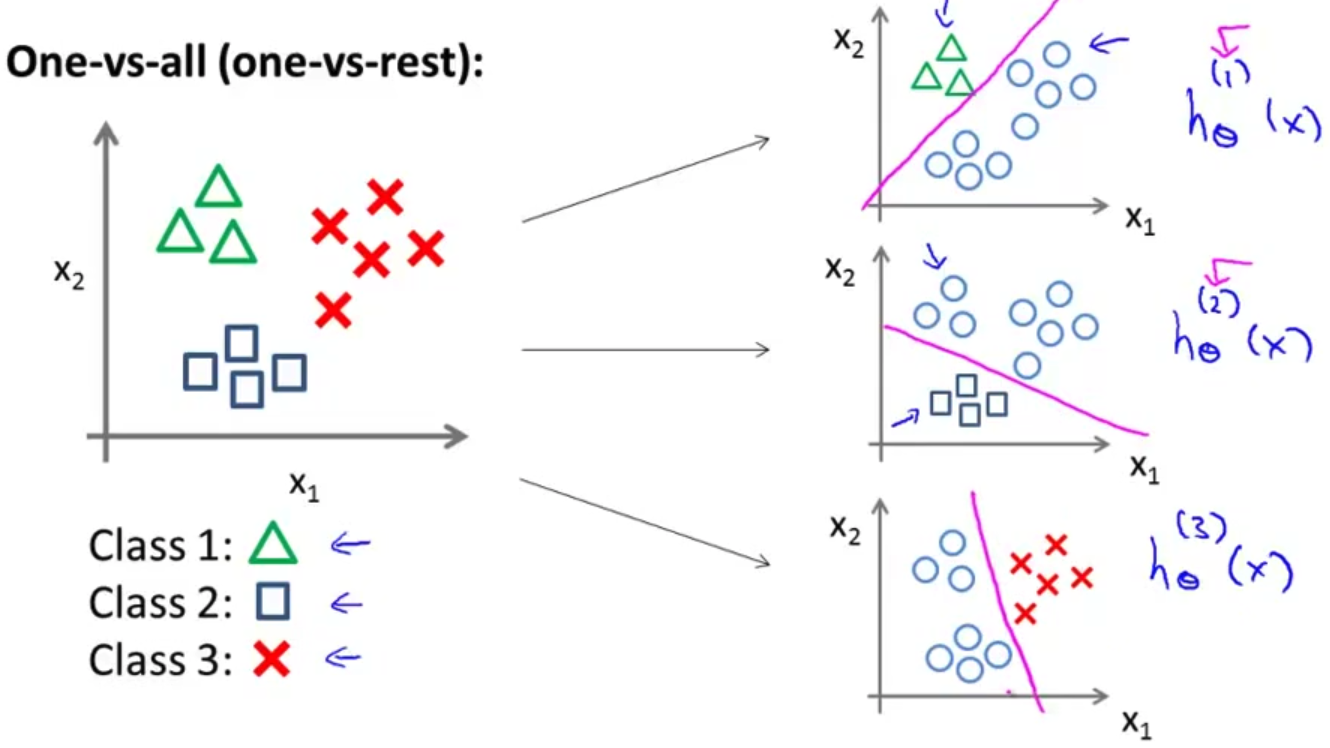
最后我们得到一系列的模型简记为: $h_\theta^{\left( i \right)}\left( x \right)=p\left( y=i|x;\theta \right)$其中:$i=\left( 1,2,3....k \right)$
最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。
总之,我们已经把要做的做完了,现在要做的就是训练这个逻辑回归分类器:$h_\theta^{\left( i \right)}\left( x \right)$, 其中 $i$ 对应每一个可能的 $y=i$,最后,为了做出预测,我们给出输入一个新的 $x$ 值,用这个做预测。我们要做的就是在我们三个分类器里面输入 $x$,然后我们选择一个让 $h_\theta^{\left( i \right)}\left( x \right)$ 最大的$i$,即$\mathop{\max}\limits_i\,h_\theta^{\left( i \right)}\left( x \right)$。
你现在知道了基本的挑选分类器的方法,选择出哪一个分类器是可信度最高效果最好的,那么就可认为得到一个正确的分类,无论$i$值是多少,我们都有最高的概率值,我们预测$y$就是那个值。这就是多类别分类问题,以及一对多的方法,通过这个小方法,你现在也可以将逻辑回归分类器用在多类分类的问题上。




